
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 따뜻함주의
- persuation
- 연결주의
- 켈트 매듭
- #정신역동
- Psychology
- 도덕발달단계론
- collectivism
- 강화
- 외측 슬상핵
- 일주율
- criminal psychology
- #산업및조직심리학
- celtic knot
- heartism
- #정신분석
- ctm
- 행동주의
- #크립키
- individualism
- memory
- 테스토스테론렉스
- 빅토리아 시대
- 심리학
- 시각처리
- 개인주의
- 집단주의
- 행동주의 치료
- sexdifference
- behavior modification
- Today
- Total
지식저장고
ANOVA(분산분석,F검정) 절차 본문
분산분석은 다루는 수준에 따라 나뉜다. 하나의 변수만을 고려할 경우 일원 분산분석(One-way ANOVA), 두개의 변수를 고려할 경우 이원 분산분석(2-way ANOVA)이라 부른다. 3원,4원도 존재할 수 있으나 보통 많은 통계 과목에서는 이원까지만 다룬다. 그러니 여기서도 일원과 이원만 다루겠다.
먼저 일원 분산분석은 다음과 같이 시행한다.
1.a level을 정하고 가설을 설정한다. 분산분석에서 가설을 non-directional밖에 존재할 수 없다. 왜냐하면 F값은 카이제곱분포처럼 y축에 기댄 모양으로, 모든 F>0이기 때문이다. 이는 F값의 중앙값이 0이 아닌 1인 이유이기도 하다. 그래서 분산분석의 가설은 non-directional밖에 없으며 영가설은 '모든 집단의 μ는 같다'이다.
2.데이터를 만들어낸다. 그리고 각 집단의 평균과 SS를 구한다. 참고로 분산분석도 각 집단의 표준편차가 모두 동일하다고 가정한다. 그리고 t검정처럼 가정이 침해되어도 결과가 크게 어긋나지 않는다.
3.MSwithin(MSe)과 MSbetween(MSt)을 만든다.
분산분석에서 사용되는 SS는 총 2가지로 나눌수 있다. 하나는 SSwithin(SSe)으로, 모집단의 SS를 나타내며 모든 집단의 SS를 합하여 구한다. 예를 들어 4개의 집단으로 실험을 한 후에 SSe을 구한다면

그리고 표준편차처럼 이것을 자유도로 나눠준 것이 MSe이다. 이 MSe는 모집단의 분산을 나타내며, 그래서 모든 집단의 자유도를 합친 것을 자유도로 사용한다. 따라서
반면에 SSbetween(SSt)은 집단간의 편차를 나타낸다. SSe가 모집단 자체의 SS라면 SSt은 모집단을 대표하는 각 표본들로 SS를 구했다. 그러나 영가설이 맞다면 SSt이든 SSe든 모집단은 동일하기 때문에 둘은 실질적으로 동일하다. 그래서 SSt은 표본평균을 이용하며 식은 다음과 같다.
이것도 SSe와 마찬가지로 자유도로 나누어준다. 총 k개의 집단을 사용했으므로 자유도는 k-1이다. 그런데 여기서 하나 알아두어야 할 게 있다. SSwithin과 달리 SSt는 표본을 거쳤기 때문에 정확히 MSbetween은 MSe와 달리 모집단의 표본 분산을 나타낸다. 그리고 표본 분산과 모분산 사이에는 잘 알려진 식이 하나있다.
이걸 그대로 MSbetween에 적용하면 nMSbetween=진짜 MSbetween이다. 그래서 MSbetween에는 n을 곱해줘야 하며 다음과 같은 식이 성립한다.

4.구한 MS들을 통해 F값을 구한다. F값은 다음과 같다.
F값은 실질적으로 같은 분산을 서로 나누는 것이다. 만약 영가설이 맞다면 모집단의 분산인 MSwithin과, 비록 중간과정을 거치긴 했지만 같은 모집단에서 올라온 표본들의 분산인 MSbetween은 사실상 같을 것이고, 그래서 F값이 1 주변에 분포할 것이다. 그리고 여기서 가설검정이 출발한다.
4.F값에서 p를 계산하고 이를 a level과 비교한다. 만약 영가설이 맞다면 F값은 1 주변에 위치할 것이다. 그러나 만약 실험적 처치가 유의미한 차이를 만들었다면, 이는 집단간 편차를 크게 하여 MSbetween을 증가시킬 것이고, 결과적으로 F값이 1보다 커질 것이다. 다만 분산분석은 단지 표본들 사이에 유의미한 차이가 존재한다는 것만 말하고, 정확히 어떤 집단이 차이를 만들었는진 말하지 않기 때문에, 사후검정을 통해 이를 알아보는 조치가 행해진다. 자세한 것은 여기1를 참고하라.
위와 같은 과정은 엑셀을 통해 단번에 끝낼 수 있다. 사실 분산분석은 매우 자주 쓰이는 방법이기 때문에 엑셀에서도 이를 한큐에 처리하는 방법을 가지고 있다.
1.데이터->데이터 분석을 클릭한다. 엑셀 프로그램에 '데이터 분석'이 없는 경우 몇가지 절차를 거쳐 이를 추가할 수 있다.
2.데이터 분석을 클릭하면 다음과 같은 창이 뜬다. 이 창에서 '분산분석:일원 배치법'을 클릭한다.
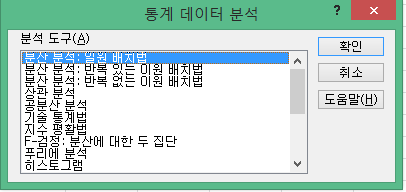
3.그러면 아래와 같은 창이 뜬다. 분산분석하려는 범위를 입력하고 a level을 입력한다.
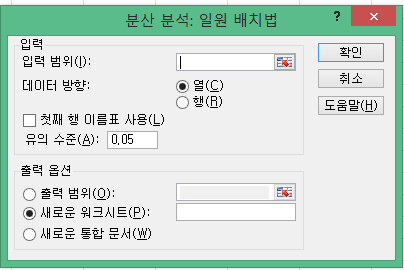
4.그러면 표가 나타난다. 표에서 처리=MSbetween, 잔차=MSwithin이다. Column=각 집단을 나타낸다. 표가 기존 데이터 위에 나타나면서 기존 데이터를 모두 날려버리니 이에 주의하자.
이원 분산분석도 위와 거의 동일하다. 특히 SSwithin은 위와 동일하다. 그러나 몇가지 면에서 이원 분산분석은 일원 분산분석에 비해 해야 할 계산이 더 많다.
먼저 이원 분산분석은 상호작용 효과(interaction effect)를 고려해야 한다. 일원 분산분석에서 측정한 것은 하나의 변인이 각 수준에서 얼마만큼의 효과가 나타나는지인데, 이를 주효과(main effect)라 한다. 주효과가 하나의 변인이 만드는 효과만 측정하는 것과 달리 상호작용 효과는 2개 이상의 변인이 서로 상호작용하는지를 측정한다. 이원 분산분석에서는 2개 이상의 변인이 사용되기 때문에 변인들 사이에 상호작용이 있는지 알아보는 것도 중요하다. 또한 여러 변인이 사용되기 때문에 사용되는 변인만큼 측정해야 하는 주효과도 늘어난다. 그래서 이원 분산분석의 경우에는 2개의 주효과를 측정해야 한다. 이와 같은 과정은 다음과 같이 시행된다.
1.유의수준을 정하고 가설을 3개 설정한다. 2개의 주효과와 상호작용 효과에 관해 영가설을 세워야 한다.
2.일원 분산분석과 동일하게 데이터를 만든다.
3.주효과들의 MSt을 구해준다. 또한 MSe를 구하고 MSinteraction을 구한다.
주효과들의 자유도는 수준에 따라 달라진다. 만약 변인1은 수준이 2개이고 변인2는 3개이면 자유도는 각각 1,2개가 된다. 이와 같은 방식으로 MSt를 구해주면 된다. dfe는 rc(n-1)로, 여기서 n=집단의 개수, r과 c는 사용된 변인의 수준 개수다. 위의 경우라면 r=2이고 c=3이다. 자유도가 일원 분산분석과 달라지는 이유는 이렇게 해야 모든 SS의 합이 ΣSS와 같기 때문이다.
한편 SSinteraction은 주효과를 기준을 할 때의 예상 평균과 실제 집단의 표본 평균을 비교하여 SS를 만들어낸다. 만약 상호작용 효과가 없다면 오로지 주효과만이 작용해야 함으로 SSinteraction은 작아질 것이다. SSinteraction은 다음과 같이 구한다.
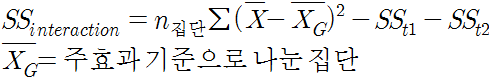
MSinteraction은 SSinteraction을 df(interaction)으로 나눠주면 된다. df(interaction)=(r-1)(c-1)이다.
4.구한 MS들로 F를 구한다. 주효과는 일원 분산분석과 동일한 방법으로 구하면 된다. 상호작용 효과는 다음과 같은 식으로 F를 구한다.
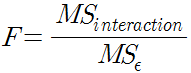
이원 분산분석 역시 엑셀을 통해 단번에 해결할 수 있다. 그 방법은 아래와 같다.
1.먼저 데이터를 엑셀에 입력한다. 2개의 변수가 나타나기 때문에 데이터 입력도 신중해야 한다. 행을 기준으로 할 경우 데이터 입력은 다음과 같이 해야 한다.
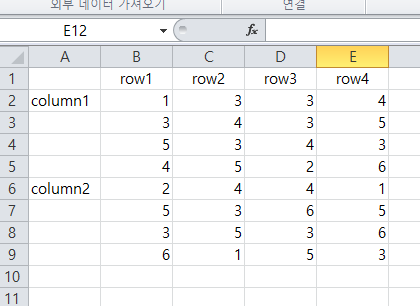
이렇게 각 변수의 수준을 같이 입력해주어야 한다. 이렇게 정리해야 컴퓨터에서 column1과 row1 하에 있는 집단의 표본이 {1,3,5,4}임을 알 수 있다.
2.데이터분석을 클릭해서 분산분석:반복 있는 이원배치법을 누른다.
3.창이 뜨면 일원 분산분석과 같은 방법으로 수행한다. 데이터 입력 시 변수를 표시한 부분도 다 같이 입력해야 한다.
4.그러면 역시 표가 나타난다. 교호작용이 상호작용 효과를 나타낸다. 나머지는 일원 분산분석과 같이 해석하면 된다.
- 이하 모두 Pagano, R. R. (2012). Understanding statistics in the behavioral sciences. Cengage Learning.pp420-433 참조 [본문으로]
'자료실' 카테고리의 다른 글
| 카이제곱분포로 모분산을 구간추정하는 방법 (0) | 2022.06.29 |
|---|---|
| 신뢰구간을 이용한 t검정 (0) | 2022.06.28 |
| 아카이브 저장고(냉동) (0) | 2022.05.23 |
| 아카이브 저장고(해동) (0) | 2022.05.23 |
| [앙겔읽기]역사의 승자는 프라뇨 투지만인가 (0) | 2022.05.23 |

