
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- #크립키
- 일주율
- sexdifference
- 행동주의
- 행동주의 치료
- individualism
- 강화
- #산업및조직심리학
- 연결주의
- celtic knot
- 빅토리아 시대
- #정신역동
- 시각처리
- criminal psychology
- 켈트 매듭
- memory
- 심리학
- behavior modification
- #정신분석
- persuation
- 개인주의
- collectivism
- ctm
- 테스토스테론렉스
- Psychology
- 집단주의
- heartism
- 따뜻함주의
- 외측 슬상핵
- 도덕발달단계론
- Today
- Total
지식저장고
심리측정학 총론 본문
심리측정학(psychometrics)은 인간의 심리와 행동을 측정하고 평가하는 방법을 연구하는 심리학이다. 심리측정학자들은 수학적 기초 위에서 심리학 연구에 필요한 수학적 측정모델을 개발하고, 이를 통해 측정결과의 분석과 해석을 돕는다. 심리측정학의 주요 영역으로는 규준만들기와 동등화, 신뢰도와 타당도, 문항분석 등이 있는데, 문항분석은 심리적 특성을 측정하기 위해 개발된 심리검사가 특정 집단이나 계층에 속한 사람들이 대답하기에 불리한 내용을 담고 있는지에 대한 분석이다.
현대의 심리측정학자들은 정교한 수학적 모델을 통해 신뢰롭고 타당한 심리검사와 측정 기술을 개발하려고 노력하고 있다. 현대 심리측정학에 따르면 유효한 심리검사(psychological test)은 다음의 특징을 가지고 있어야 한다.
- 표준적 절차(standarized procedure): 심리검사는 정해진 절차에 의해 시행되어야 하며, 절차는 누구에게나 동일하고 보편적인 형태여야 한다.
- 행동 샘플(behavior sample): 심리검사는 측정하는 행동과 깊게 관련된 표본에 기반하여 만들어지며, 표본은 모집단을 충분히 대표할 수 있어야 한다.
- scores/categories: 검사결과는 반드시 점수로 나타나야 하며, 점수에는 양적 점수와 분류도 포함된다. 검사상 점수(observed score)는 항상 실제 점수(true score)와 오차가 있는데, 오차가 적을수록 신뢰할 수 있는 검사이며, 이때 observed score는 다른 행동이 아니라 측정하고자 한 행동을 가장 잘 대표해야 한다.
- norms/standards: 검사결과를 비교할 기준이 있어야 한다. 검사결과가 점수를 나올 경우 비교할 평균과 준거가 있어야 하며, 분류의 경우도 평가준거가 있어야 한다. 준거는 모집단에서 제공되어야 하는데, 대표적으로 WAIS 검사에서는 개인의 점수가 평균과 얼마만큼 떨어져 있는지 알 수 있다.
- 행동 예측(prediction of non-test behavior): 검사결과는 검사에서 직접적으로 묻지 않은 행동을 예측할 수 있어야 한다. 이것이 심리검사의 존재 이유이다.
심리측정의 역사
인간의 심리를 측정하고 평가하려는 역사는 대단히 오래되었다. 사실 어느 문명권에서나 사람을 평가하는 틀과 사람의 본성에 관한 이론이 존재하기 마련이다. 이중 서양에서 처음으로 심리를 측정하기 위해 고안된 체계적인 이론은 아리스토텔레스에 의해 제시되었다. 그는 당대의 다른 철학자들이 그랬듯이 관상학(physiognomy)을 믿었는데, 그는 관상을 통해 인간의 성격을 측정할 수 있다고 믿고 이를 바탕으로 <관상학>을 저술하였다. 이러한 믿음은 19세기 초까지 계속 이어져왔으며, 사실 현대 한국에서도 상당한 영향력을 끼치고 있다.
관상학 이후에는 골상학이 등장했는데, 골상학은 사람의 두개골 모양을 통해 인간의 성격을 알 수 있다는 주장이었다. 이러한 주장은 의사 갈에 의해 체계화되었고 곧 유럽 전역에 퍼져나갔다. 의외로 골상학은 빠르게 과학계에서 퇴출되었지만, 대중적인 인기를 누리며 널리 번져나갔다. henry lavery는 이에 호응하여 psychograph라는 기계를 발명했는데, 이 기계는 머리의 울퉁불퉁함을 측정하여 골상학적으로 사람의 성격을 예견하는 기계였다. 이 기계는 인간의 머리 부분을 32개로 나누고 각 부분이 튀어나온 정도를 1에서 5점 사이로 평가했는데, 비록 기반이론이 틀렸고 방법론도 조악했으나 자동으로 측정치를 산출하는 최초의 심리측정 시도였다.
심리를 측정하려는 최초의 과학적 시도는 정신물리학자들에 의해 시행되었다. 정신물리학자들은 자극과 자극에 대한 인간의 반응에 관심이 많았는데, 이를 위해 역치라는 기준을 최초로 제시했다. 이들은 역치를 측정하기 위해 주어지는 자극을 미세하고 조정했고, 피험자의 50% 이상이 반응하면 역치로 여기자는 기준을 제시하였다. 또한 수학을 사용하여 측정 결과를 표현하였다. 이들의 목표는 모든 인간에게 적용되는 기본적인 심리적 법칙을 찾는 것으로, 개인차에 더 관심을 가지는 현대 심리측정학과는 차이가 있었다. 이런 차이는 심리학 초창기에도 존재했는데, 많은 고전심리학자들은 정신물리학과 달리 심리적 개인차를 찾는데 주력하였다. 분트, 카텔, 찰스 스피어만, 프랜시스 골턴 등이 바로 그런 학자였다. 이들은 주로 인지적 능력을 측정하는데 관심을 가졌으며, 지금과 같은 심리검사보다는 생리적 측정을 통해 이를 달성하고자 하였다.
심리학의 창시자 분트는 생각의 신속성을 측정하기 위해 thoughtmeter를 발명했다. thoughtmeter는 눈금이 그려진 굽은 자와 그 위에서 흔들리는 진자로 구성되어 있는데, 피검사자는 검사자가 지시하는 순간 진자가 가리키는 눈금을 얘기해야 했다. 어찌됬건 진자가 사람보다 빠르기 때문에 사람이 말한 위치와 실제 위치는 조금 차이가 나는데, 검사자는 진자 위에 설치된 시계를 통해 본래 위치를 역산해서 둘의 차이를 파악할 수 있었다. 최초의 지각 속도 측정이라 할 만한 이 측정은 정신물리학처럼 인간의 평균적인 지각 속도를 젤 수 있는 동시에, 각 개인의 속도 차이, 즉 개인차도 알 수 있었다.
유전학자이자 우생학자였던 골턴은 분트보다 더 노골적으로 개인차를 측정하려고 했다. 골턴은 백인 부자들이 다른 사람보다 유전적으로 우월하다는 주장을 증명하고 싶어했는데, 이를 위해 다양한 방법론적 시도를 하였다. 그는 잘사는 백인들이 지능이 우월하다고 주장했는데, 이를 입증하기 위해 그는 개인의 반응속도(RT)와 sensory discrimination task를 사용했다. sensory discrimination task는 서로 거리가 가까운 점을 변별하는 시지각 과제로, 골턴은 RT와 시각적 정확성이 지능의 척도라고 믿었다. 이외에 그는 유전자와 개인의 성공의 관계를 보여주기 위해 상관분석의 전단계에 해당하는 기법을 고안했으며, 이외에도 성격을 측정하는 방법을 고안했다. 비록 상관분석을 제외하면 그의 심리학적 유산은 오직 영미의 인종차별주의 멍청이들에게서만 계승되고 있지만, 동시에 골턴은 심리측정의 아버지로 평가받고 있다.
제임스 카텔(James McKeen Cattel)은 전반적인 정신적 능력(mental power)에 관심을 가진 학자였는데, 분트가 지각 속도에만 관심을 가졌던 것을 너머 전반적인 정신적 능력, 즉 지능을 측정할 검사를 만들고자 시도하였다. 이러한 노력은 다양한 지능검사의 개발로 이어진다. 한편 카텔의 제자였던 위슬러(wissler)는 골턴이 개발한 sensory discrimination task에 관심이 많았는데, 그는 sensory discrimination task가 실제로 학업적 성공을 예측한다고 믿었다. 비록 그의 엄밀한 연구는 sensory discrimination task가 학업과 1도 관련이 없음을 증명해 버렸지만, 심리적 측정의 타당성에 대한 최초의 검증 시도는 그를 심리학의 아버지 명단에 올리는데 공헌하였다.
카텔이 지능검사 연구에 주력하긴 했지만, 최초로 만들어진 심리검사는 이전에 다른 연구자에 의해 만들어졌다. 알프레드 비네는 프랑스의 심리학자였는데, 그는 아이들의 학업성취도를 지능이라고 여기고 이를 측정하려고 시도하였다. 그는 동료 연구자 시몽과 함께 비네-시몽 검사를 만들었는데, 이 검사가 세계 최초의 지능검사이자 세계 최초의 심리검사이다. 한편 지능연구자인 찰스 스피어만은 다른 방면에서 심리측정학에 공헌했는데, 그는 지능검사의 통계적 기초를 만들면서 처음으로 observed score의 개념을 제시했다. 즉 그는 처음으로 심리측정의 결과가 실제 사실과 오차를 가진다는 개념을 심리학적으로 공식화하였다.
심리검사
심리검사(psychological testing)는 인간의 행동 또는 정신을 객관적이고 표준화된 방법을 통해 측정하는 도구이다. 주로 설문지의 형식을 가지지만 피검자가 손으로 조작하거나 육체적으로 반응하게 하는 검사도 많다. 위에서 말했듯이 심리적 실재는 매우 모호하기 때문에 심리검사에서 측정하는 개념은 대개 구성개념(construct)의 형태를 띠고 있다. 구성개념은 조작적 정의와 비슷한 것으로, 대상을 실제로 관찰하는 대신 이를 반영하는 여러 지표를 사용하여 간접적으로 관찰하는 것이다. 심리검사가 측정하는 지능, 정신병리 등은 눈으로 직접 관찰할 수 없기 때문에 이러한 간접적인 지표를 통해서만 관찰할수 있으며, 때문에 다른 물리적 측정대상에 비해 측정에 불완정성과 불안정성이 존재한다.
심리검사는 3가지 기준을 만족해야 한다. 먼저 심리검사는 검사가 기초한 이론을 잘 반영한 상태에서 만들어져야 한다. 가령 자존감을 측정한다면, 자존감이 행동적으로 드러나는 특징에 대해 세세하게 알고 있어야 제대로 된 검사를 만들수 있을 것이다. 그냥 주먹구구식으로 '나는 자신이 있다'같은 한문장으로 자존감을 측정하려 든다면, 이는 필히 실패로 이어진다.
또한 심리검사는 표준화의 과정을 거쳐야 한다. 표준화는 심리검사가 일반인을 대상으로 검사해도 편향되는 결과가 나오지 않도록 교정하는 절차이다. 예를 들어 노인의 실생활능력을 평가하는 설문지를 만든다고 해보자. '잘 걷는다.'거나 '암이 없다.'와 같은 질문은 큰 편향을 낳지 않겠지만 '집안일을 잘한다.'와 같은 문장은 그러지 못한다. 왜냐하면 2020년에 노년기를 보내는 많은 남성 노인은 부엌에 들어가기만 해도 큰일난다는 교육 속에서 살아와서 집안일이라곤 일절 못하는 사람도 있기 때문이다. 이처럼 특정 집단에게 편향된 결과를 낳는 실수를 막기 위해서는 검사를 표준화 해야한다.
표준화를 실시할때 학자들은 먼저 표본집단을 선정한다. 대부분의 심리학 연구는 그냥 주변에서 구하기 쉬운 대학생으로 진행하지만, 표준화를 하려면 모든 인구집단의 특성이 반영되어야 하기 때문에 적당히 큰 표본에서 최대한 인구집단이 균질하게 들어가도록 표본이 선정된다. 교과서에서만 배우는 층화추출법도 이럴때 사용될 수 있으며, 이렇게 모인 인구집단의 분포에 대한 정보는 논문에 같이 적혀야 한다. 또한 표본은 목적에 맞게 하위집단을 포함해야 하는데, 가령 WISC같은 경우에는 성인기 이전 모든 아이들이 포함되어야 하며 반대로 K-WAIS는 외국인 데이터는 포함할 필요가 없다. 그리고 이렇게 표준화된 검사는 최대한 지시사항을 자세하게 하여 다른 요인에 의한 오염을 방지해야 한다.
마지막으로 이는 임상장면에서의 심리평가에서 특히 중요한데, 검사는 피검자에 맞게 작성되어야 한다. 중증의 정신질환을 앓고 있는 사람들은 여러 이유로 집중력이 많이 저하된 경우가 많은데, 즉 하나에 집중해야 하는 시간이 너무 오래 걸리는 검사는 이들에게 적합하지 않다. 또한 자폐아들은 언어적 소통이 힘들기 때문에 언어를 사용해야 하는 WAIS보다는 그림을 위주로 돌아가는 RPM 계열의 검사를 사용하는게 맞다. 검사가 피검자에 맞지 않으면 특정 집단이 실제와 달리 점수가 너무 높거나 낮게 나올 수 있는데 이를 test bias라 한다. 이처럼 검사는 피검자의 특성에 맞게 만들어져야 한다.
심리검사 문항을 선별하는 2가지 방법이 있다. 논리적/이성적(logical/rational) 문항 선정 방법은 안면/내용 타당도에 근거하여 측정하고자 하는 구성개념에 논리적으로 부합하는 문항을 선별하는 방법이다. 제작자의 주관이 반영되며, 간단하고 직관적이기 때문에 아주 자주 사용된다. 그러나 안면 타당도가 있다는 말은 피검자도 이게 뭐하는 검사인지 알기 쉽다는 말로, 그래서 피검자가 반응을 허위로 꾸밀 수 있다. 또한 실제 연구에 따르면 논리적/이성적 방법으로 선정된 문항이 실제 구성개념을 적절히 측정하지 못하는 경우가 많다.
반면에 경험적(empirical) 문항 선정 방법은 복잡하고 돈이 많이 들어서 잘 안쓰이지만, 구성개념을 적절히 측정할 수 있다. 경험적 방법은 철저하게 데이터에 의지해서 문항을 선정하는 방법으로, 문항 수집 과정은 논리적/이성적 방법과 동일하나 선별에는 선험적 논리가 개입하지 않는다. 가령 조현병 진단도구를 만드는 경우, 경험적 방법을 사용하는 연구자는 정상인과 조현병 환자에게 예비문항들을 테스트하여 조현병 환자에서 빈도가 높게 나온 것만 선별한다. 설령 그 문항이 '나는 정상이고 아주 잘 산다.'라 할지라도 선별된다. MMPI가 바로 경험적 방법으로 제작된 검사이다.
심리검사는 일반적으로 질문지형 검사와 투사 검사로 나뉜다. 질문지형 검사는 피검자가 어떠한 설문지의 명확한 질문에 응답하게 하고 이 응답에 기반하여 피검자를 측정하는 검사이고, 투사 검사는 모호한 자극을 제시한 후 이에 대한 피검자의 반응을 분석하여 피검자를 측정하는 검사이다. 대개 기초 심리학 연구에서는 질문지형 검사가 많이 쓰이나 제대로된 투사 검사는 임상심리학에서 많이 쓰인다. 최근에는 다른 형태의 심리검사도 존재하나,1 심리측정학에서 다루는 심리검사는 대개 질문지형 검사이다.
Latent variable
우리가 observed score를 구하는 이유는 진짜 점수, 즉 검사가 측정하고자 하는 진정한 값을 조금이라도 알기 위해서다. 오차 속에 숨어있으나 우리가 진정으로 알고 싶어하는 이 변수를 latent variable이라 하며, observed score는 latent variable의 실제 값을 구하기 위한 방편이다. 사실 측정의 궁극적인 목표는 latent variable의 값이나 실제로 우리가 알아내는 것은 모두 observed score다. 평균도, 표준편차도, 상관계수도, 모두 observed score로 latet variable의 진정한 값에는 이르지 못했다. 심리측정학에서는 Latent variable을 보통 T라고 부르며, 반대로 observed score는 Y라고 부른다.
Y=T가 아니다. 그러기에는 몇가지 장애물이 가로막고 있다. 먼저 Y=f(T)+ε이다. 그래서 Y=T가 아니며, 설령 f(x)의 형태가 알려지더라도(보통은 알려져 있지 않다) 오차가 존재하기 때문에 여전히 예측할 수 없는 부분이 존재한다. Y가 T와 얼만큼 비슷한지도 알기 힘든게, T는 측정불가능하기 때문에 관련성도 구할 수 없다. 게다가 어떤 값은 시시각각 변하기 때문에, T가 고정되어 있지 않다. 이는 앞의 두가지 문제가 다 해결되더라도 고정된 참 T값을 포착할 수 없음을 보여준다. 이러한 문제들로 인해 심리측정으로 T를 아는 것은 매우 힘들며, 이것을 극복하기 위한 노력이 바로 심리측정학의 역사이다.
Scaling model
측정(measure)은 조사하는 대상의 어떤 특성에 알맞는 값을 배정해 주는 것이다. 측정을 통해 부여되는 값은 Y이며, scaling score라고도 부른다. Y가 부여되는 구조는 측정이 실시되는 구조, 즉 scaling model(measurement model, psychometric model)에 따라 행해진다. scaling(척도화)은 scaling model을 개발하는 것으로, 대상의 측정값에 일정하고 객관적인 의미를 부여하기 위한 절차이다. 측정값들이 어디서 기인했는지에 대한 관점에 따라 척도화 방법이 달라질 수 있는데, 측정되는 사람들의 차이에 의해 측정값들이 생성된다면 사람중심 방식, 측정하는 도구(대개 한 문항)의 차이에 의해 생성된다면 자극중심 방식이 사용된다.
사람중심 방식(subject-centered scaling)은 측정값들의 차이가 측정되는 개인들의 차이에 의해 발생한다고 보고, 이러한 개인차를 측정하는 척도를 개발하는 방식이다. 예를 들어 사람들에게 암벽 등반을 시킬 때, 사람들이 올라간 최대 높이의 차이는 사람들의 암벽 등반 능력의 차이에 의해 생길 것이다. 사람중심 방식의 척도화는 이러한 가정하에 사람들의 개인차(암벽 등반 능력)를 측정하는 척도를 개발하는 것이다. 사람중심 방식으로 개발된 척도는 사람들의 Y를 한 연속선상에 배열하고, 그 결과를 등간척도로 구성해 서로 비교한다. 사람중심 방식은 가장 널리 쓰이는 척도화이며, 상당히 많은 심리검사가 사람중심 방식으로 제작되었다.
사람중심 방식을 사용할 때는 2가지 가정이 필요하다. 먼저 심리검사의 경우 척도에서 쓰이는 모든 항목들이 서로 동등하고 타당하고 신뢰로워야 한다. 대부분의 심리검사는 여러 문항(item)을 이용해 하나의 특성을 측정하는데, 사람중심 방식은 이 문항 하나하나가 모두 충분할 만큼 타당도와 신뢰도를 확보했다고 가정한다. 그래서 이 문항들의 점수를 합산하여 개인의 Y를 제공할 수 있다. 또한 사람중심 방식 척도는 참조틀(frame of reference)이 있어야 한다. 즉 사람중심 방식으로 만들어진 척도는 Y를 평가할 기준이 있어야 한다. 가령 WAIS의 경우 평균은 100, 표준편차는 15로, 이를 통해 개인의 IQ가 어떤 위치에 있는지 평가할 수 있으며 실제로 WAIS 검사에서도 개인의 IQ가 우수한지 아닌지를 평가하는 기준을 제공한다.
자극중심 방식(stimulus-centered scaling)은 측정값들의 차이가 문항의 차이에 있다고 보고 문항의 차이를 분석하는 방식이다. 앞에서 암벽 오르기를 예로 들었는데, 사실 암벽의 종류에 따라 사람들의 성적도 달라질 수 있다. 높이 20미터에 튀어나온 돌이 30cm 정도의 정사각형이면 Y의 차이는 매우 작아지고 거의 모두가 2미터를 찍을 것이다. 그러나 매우 추운 툰드라에서 높이 20미터의 매끈한 벽을 오르게 하면 반이라도 오르는 게 매우 힘들어질 것이다. 만약 이 두 암벽을 오르는 사람이 있다면, 같은 사람임에도 불구하고 올라간 높이나 등정 성공여부가 매우 달라질 것이다. 이처럼 Y의 차이는 문항의 차이에 의해서도 생길 수 있기 때문에, 자극중심 방식은 문항에 따른 점수차이를 연속선상에 배열하고 이를 통해 문항을 평가한다. 이러한 방식은 문항을 개발하는데는 쓸 수 없지만, 여러 문항을 종합한 척도를 개발하는 데는 필요하다. 왜냐하면 우리가 T에 최대한 가까운 Y를 산출하기 위해서는 타당도와 신뢰도가 높은 문항을 선별해야 하는데, 그러려면 각 문항을 평가해야 하기 때문이다. 그래서 모형적합도를 산출하거나 model testing에 자극중심 방식이 잘 사용된다.
모델을 평가하는 지표 중 하나는 GFI이다. GFI(Goodness of Fittness Index)는 모델에서 예측한 값과 실제 값이 얼마나 비슷한지에 대한 지표로, SS를 통해 계산된다. 공식은 아래와 같다.
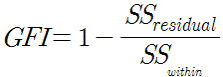
예측치와 실제 값이 비슷하면 SSresidual이 SSwithin과 비슷해야 하기 때문에, GFI가 1에 가까울수록 좋다. 사족으로 모델을 평가할때 사용되는 척도수준은 문항의 척도수준과 다르다. 예를 들어 심리검사이 경우 각 문항은 명목 척도거나 서열 척도일 수 있지만, 모델 평가는 예측치와 실제값의 차이를 z값으로 변환하여 시행하기 때문에 등간 척도이다.
Norm
norm은 심리검사를 통해 얻은 점수를 평가하는 기준으로, Y의 분포를 묘사하는 기술통계이다. 여기에는 평균, 분포, 측도 등 다양한 기술통계가 포함되는데, 이들은 모두 norm을 만들기 위해 동원된 표준화 집단(norm group, standarized group)에 대한 묘사이다. norm을 통해 심리검사에서 얻은 raw score가 충분히 의미를 해석할 수 있는 interpretable information으로 변환되는데, 심리학에서 interpretable information은 보통 백분위수나 표준화 점수로 나타난다.
백분위수(percentile, 퍼센타일)는 특정값이 전체 집단과 비교했을때 가지는 상대적 위치를 나타내는 값이다. 즉 특정 Y가 전체 집단에서 어느 정도의 순위인지를 보여주는 값이며, 보통 백분위로 표현된다. 보통 Px로 표현되는데, x는 해당값이 전체 집단에서 차지하는 순위이다. 가령 Y=17이 상위 20%에 드는 점수인 경우 Y1=P80이다. 중앙값은 P50이고, 사분위수는 P25, P75이다. 백분위수가 어떤 값의 상대적 위치를 알려주기 때문에 순위가 필요한 분야(수능)에서 잘 사용되지만, 백분위수는 순서 척도이기 때문에 연구에서는 잘 쓰이지 않는다.
표준점수(standard score)는 원점수를 표준화 집단의 평균과 표준편차를 중심으로 변환한 점수이다. 가장 대표적인 표준점수가 z값인데, z값은 (Y-M)/s로 나타난다. z값은 어떤 집단이 정규분포를 따를때 사용되는 값으로, 등간척도이기 때문에 여러 통계적 기법을 적용할 수 있다. 또한 등간척도이기 때문에 점수간 차이를 보존하면서도, 어떤 점수든 정규분포상의 한 점으로 바꾸기 때문에 두 원점수를 비교하는데 용이하다. 왜냐하면 서로 다른 norm group을 가진 두 원점수는 점수체계와 분포경향이 달라 원점수를 그대로 비교할 수 없지만, 두 원점수를 z값으로 환원하면 동일한 정규분포 하에서 서로를 비교할 수 있기 때문이다. 다만 이는 각 원점수의 norm group이 정규분포를 따를때의 얘기로, 만약 한 집단의 skewness가 크면 z값으로 둘을 비교할 수 없다.
현존하는 표준점수들은 대개 z값의 변형이다. 예를 들어 T점수는 MMPI를 비롯해 다양한 분야에서 사용되는데, 평균은 50이고 표준편차는 10이다. 이는 달리 말하면 T=10z+50이라는 말이다. 또한 IQ는 평균이 100이고 표준편차는 15인 정규분포를 그리는데, 이런 경우 IQ=15z+100이다. 이렇듯 T점수나 IQ, GRE 점수 등 대부분의 표준점수가 z값에 기반하며 z값을 통해 계산되거나 반대로 z값으로 역산될 수 있다.
item statistics
item analysis는 심리검사의 문항이 대상을 측정하는데 적절한지를 분석하는 것이다. 앞에서 사람중심 방식이 척도화에서 가장 많이 사용된다고 하였다. 그러나 사람중심 방식을 사용할때는 각 문항이 모두 충분히 타당하고 신뢰롭다고 가정했는데, 실제로 아무 근거없이 그럴 것이라고 믿는 것은 잘못되었다. 그래서 심리학자들은 각 문항이 얼마나 대상을 잘 측정하는지 평가하는게 item analysis인데, item analysis는 이를 위해 고안된 item statistics를 통해 잘 수행될 수 있다.
item statistics는 Y가 연속적인 값(이거나 그렇게 보이는 값)일때 5가지가 있다. 평균, 분산, 공분산, 표준편차, 상관계수가 그것이다. 이때 item statistics는 각 문항을 대상으로 행해진다. 즉 item statistics로서의 평균은 한 문항의 점수평균이다. 여기서 공분산과 상관계수는 반드시 두 문항이 함께 포함되어야 하기 때문에 그 가짓수가 문항수의 제곱으로 늘어나며, 보통 대각선을 중심으로 대칭인 matrix를 만들어 표현한다. 하지만 Y가 dichotomous한 값을 가지는 경우에는 평균과 분산, 표준편차를 따로 정의하지 않는다. 왜냐하면 값이 이산적인 경우 평균은 단지 1점이 전체에서 차지하는 횟수이고, 분산도 그 횟수에서 자동으로 계산되기 때문이다. 이 경우 공분산과 상관계수만이 따로 item statistics로 정의된다.
Y에 대한 item statistics를 정의하면 문제가 좀 복잡해진다. Y에 대한 item statistics는 각 개인의 점수, 평균, 분산이 정의되는데, 분산의 계산은 특히 복잡해진다. 왜냐하면 단지 숫자를 더하기만 하면 되는 개인점수와 평균과는 달리, 분산은 각 문항의 분산은 물론이고 문항들의 공분산까지 합쳐지기 때문이다. 그래서 Y에 대한 공분산은 아래와 같이 정의되는데, 이때 2배를 해주는 이유는 해당 항이 매트릭스의 반쪽만 나타내기 때문이다. 그렇기 때문에 거기에 2를 곱하여 나머지 쪽 매트릭스의 공분산도 포함된다.
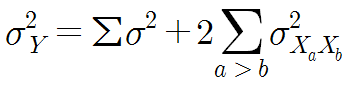
item analysis
item analysis는 item statistics를 가지고 심리검사를 분석/제작하는 것이다. item analysis를 수행하는 학자들은 되도록 검사가 사람들을 잘 변별하도록 만드는 것을 목표한다. classic item analysis에서는 보통 예/아니오로 대답하는 심리검사를 통해 두개의 집단을 변별하는데, 이러한 검사의 대표적인 예가 사람들을 정상/임상집단으로 나누기 위해 제작된 MMPI가 있다. 이처럼 item discrimination이 잘되는 문항을 선발하기 위해서는 아래 5가지 지표가 주로 사용된다.
endorsement rate는 문항에서 Yes가 차지하는 비율이다. 보통 π로 표기되는데, endorsement rate는 되도록 50%가 적당하다는 것은 굳이 말하지 않아도 알 것이다. 분산은 우리가 아는 그 분산으로 수식으로는 π(π-1)로 표기되는데, 분산이 넓을수록 사람들을 더 잘 나누게 되기 때문에 분산이 큰 문항일수록 좋은 문항으로 취급된다. π가 50%면 분산이 가장 최대가 되기 때문에, 다시 한번 endorsement rate는 50%가 좋다.
index of discrimination(discrimination index)은 점수의 상위권과 하위권이 해당 문항에서 차이를 보이는 정도이다. 즉 총 검사점수를 기준으로 상위권과 하위권이 있을때, 문항이 적절하다면 상위관과 하위권의 응답도 극명하게 갈릴 것이다. 통상적으로는 상/하위권 비율을 30%로 잡으며 상위권의 Y평균에 하위권의 Y평균을 빼서 구한다. D로 표기하며 D>2면 적당하다고 보고 4보다 크면 매우 좋다고 평가된다.
point-biserial correlation(item-to-total correlation)은 문항과 Y의 상관관계 정도이다. index of discrimination의 상위호환이라 볼 수 있겠다. 이 값이 0보다 작으면 부적절한 문항이라고 여겨져 제거되며, R에서는 r과 동일하게 취급되어 계산도 cor로 한다. 매우 사용하기 좋은 값이지만 응답이 절대적으로 이산적인 경우에만 사용할 수 있다. 즉 6점 리커트 척도를 3점 이하와 3점 이상으로 나누어 코딩한다고 하면 쓸 수 없다. 수식은 아래와 같다.
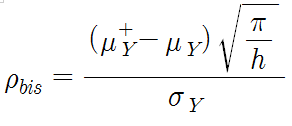
biserial correlation은 point-biserial correlation의 상위호환으로, biserial correlation은 본질이 어떻든 값이 이산적으로 나타나는 모든 검사에 적용할 수 있다. 대신 통계량이 약간 달라서 R에서 계산할때 별도의 함수가 필요하다. 수식은 아래와 같다. 아래에서 h는 유의확률이 1-π인 z를 말한다.
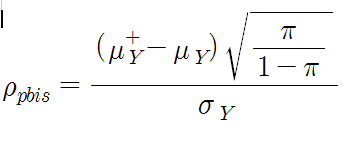
신뢰도와 타당도
과학 개론에서도 말했지만 신뢰도와 타당도는 심리검사를 평가하는 척도이기도 하다. 신뢰도는 검사결과가 얼마나 안정적인지, 타당도는 검사가 측정해야 하는 대상을 실제로 잘 측정하는지 평가하는 척도이다. 하지만 일반적으로 타당도가 높으면 신뢰도도 높다. 신뢰도는 주로 상관관계 측정과 비슷한 크론바하 알파(Cronbach α)로 평가하며 .7 이상이면 연구에 양호, .9 이상이면 의료목적으로 사용가능하다. 반면 타당도는 아직 이를 정확하게 평가하는 통계적 방법이 없다. 심리검사의 신뢰도와 타당도를 평가하는 방법은 다양하지만 대표적인게 몇가지 있다.
신뢰도
신뢰도(reliability)는 수학적 측면에서 말하면 Y와 T의 상관관계이다. 즉 Y가 얼마나 T를 잘 반영하는지의 정도가 신뢰도이다. 그냥 보면 타당도를 잘못 말하는 것 같지만, 신뢰도 지표(reliability index)는 수식에서도 ρ(YT)로 표기된다. 심리측정학에서는 Y=T+ε라고 가정하는데, 이 모델은 classical true-score model이라 불리며 신뢰도에 대한 수학적 개념을 정립하는 기반이다. 심리검사 환경에서 신뢰도는 시험환경, 응시자의 단기적 심리상태(불안, 주의, 동기, 피로 등), 검사자의 무의식적 행동, 채점상 주관성, 문항구성에 의해 낮아질 수 있는데, 심리측정학자들은 주로 문항구성에 의한 오염을 최소화하고자 노력한다. classcial true-score model에 따르면 신뢰도는 아래와 같이 구할 수 있다.
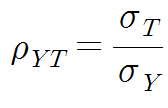
증명은 다음과 같다.

동형검사(parallel test)
동형검사는 서로 같은 T를 측정하는 동일한 검사를 말한다. 즉 어떤 두 검사가 같은 T를 측정하고 비슷한 Y를 내면 이를 동형검사라고 한다. 수학적으로 동형검사는 T가 같아야 하고, 오차의 분산이 같아야 한다. 여기서 동형검사가 가지는 특징이 나타나는데, 동형검사는 Y의 평균과 분산, Y값과 그 Z값의 공분산이 같다. 그에 대한 증명은 아래와 같다.
E(Y)=E(T)+E(ε)=E(T) -> 1번 증명
var(Y)=var(T)+var(ε). 그런데 정의에 따라 var(ε1)=var(ε2) -> 2번 증명
2번 증명에 따라 3번도 증명
동형검사가 중요한 이유는 2가지가 있다. 먼저 동형검사를 사용하는 동형검사 신뢰도는 다른 어떤 신뢰도 측정방법보다 좋다. 더 중요한 것은, 동형검사를 통해 신뢰도를 구할 수 있다는 것이다. 위에서 나타난 신뢰도 지표는 T에 대한 통계량을 포함하기 때문에 측정할 수가 없다. 하지만 동형검사를 활용하면(완벽한 동형검사의 제작여부가 가능한지는 둘째치고) 신뢰도가 두 동형검사의 신뢰도에 대한 공식으로 바뀌기 때문에 얼마든지 측정을 통해 구할 수 있다. 정확한 공식의 형태는 아래와 같다.
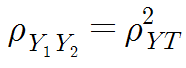
증명은 아래와 같다.

한편 오차의 분산은 standard error of measurement라고 하는데, standard error of measurement는 신뢰도에서뿐만 아니라 다른 통계에서도 중요하게 사용된다. 왜냐하면 모델이 현상을 정확하게 예측했는지 평가하는데 사용하기 힘들기 때문이다. 모델의 예측값과 실제 값을 비교해서 standard error of measurement를 산출할때 이 값이 작을수록 좋은 모델로 판단된다. standard error of measurement는 다음과 같은 식으로 구해진다.
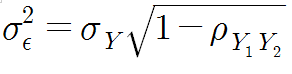
증명은 아래와 같다.

신뢰도의 측정
위의 식에서 보듯이 이제 동형검사를 만들면 자연히 신뢰도를 측정할 수 있지만, 사실 이상적인 동형검사를 만드는 것도 불가능에 가깝다. 동형검사의 조건은 생각보다 충족하기 힘들고, var(ε)를 구하는 것 자체가 불가능에 가깝다. 그렇기 때문에 실제 연구현장에서는 approximately parallel measurement가 사용되며, 이 밖에도 다양한 방법이 사용된다.
검사-재검사 신뢰도(test-retest reliability, the coefficient of stability)는 같은 검사를 동일인에게 두번이상 시행하는 방법으로, 두번이상 시행한 후 각각의 Y의 상관관계를 구하는 방법이다. 검사-재검사 신뢰도는 2가지 가정이 성립해야 하는데, 검사를 시행하는 동안에 T와 standard error of measurement가 동일해야 한다. 같은 검사를 하는데 어떻게 T가 달라지는지 의문일 수 있는데, 첫번째 검사를 하면서 생긴 태도가 두번째 검사에 영향을 끼쳐서(carry-over effect) T가 달라질 수도 있다. 이외에 학습효과의 위험성도 있기 때문에 지능검사를 비롯한 인지기능 검사에서는 잘 쓰이지 않는다.
동형검사 신뢰도(alternative form reliability, the coefficient of equivalance)는 앞에서 말했듯이 동형검사를 만들어 둘을 비교하는 방법이다. 연구자들은 자신이 만든 검사의 동형검사를 하나 더 제작하고 둘을 시행해서 나온 결과를 비교하여 신뢰도가 얼마나 높은지 구하는데, 앞에서 말했듯이 동형검사는 엄밀히 approximately parallel measurement이기 때문에 Y의 평균과 분산이 비슷해야 한다는 최소한의 가정이 만족되어야 한다. 이 방법이 제일 신뢰도가 높긴 하지만 비슷한 검사를 만드는데 비용이 많을 뿐더러 기껏 만든 검사가 비슷한지도 알기 힘들기 때문에 새로운 검사를 평가하는 상황 외에는 잘 쓰이지 않는다.
internal consistency reliability는 검사 내의 문항들을 이용해서 신뢰도를 구하는 방법으로, 가장 경제적인 방법이자 제일 널리 쓰이는 방법이다. internal consistency reliability를 사용하는 학자들은 주로 검사를 부분적으로 나누거나 검사에 관련된 통계량을 사용하여 신뢰도를 만든다. 대표적으로 쓰이는 internal consistency reliability는 반분신뢰도, 크론바하 a, VCA가 있다.
반분신뢰도(split-half reliability, coefficient of equivalance)는 같은 검사를 앞뒤나 홀짝으로 문항을 나누어 부분검사를 만들고, 두 검사를 비교하는 방법이다. 부분검사의 개수는 보통 2개이나 더 많은 수로도 만들 수 있다. 반분신뢰도를 구하는 공식은 다음과 같은데, 이를 spearman-brown prophecy formula라고 한다.
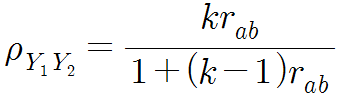
증명은 아래와 같다.
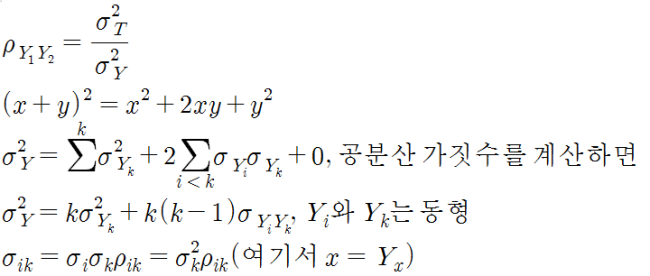
이를 원래 공식에 대입하고 약분하면
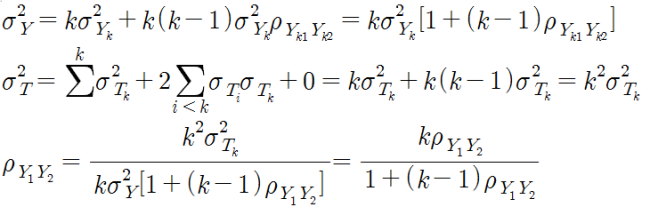
크론바하 a(cronbach α, cronbach's alpha, 크론바흐 α, α)는 제일 널리 쓰이는 신뢰도 측정 방법으로, 모든 가능한 부분검사의 평균이다. 크론바하 a의 공식은 다음과 같다.
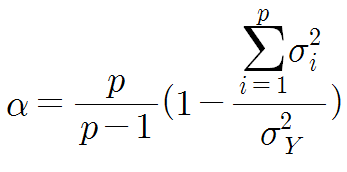
크론바하 a는 신뢰도 공식에서 다음과 같이 유도된다.
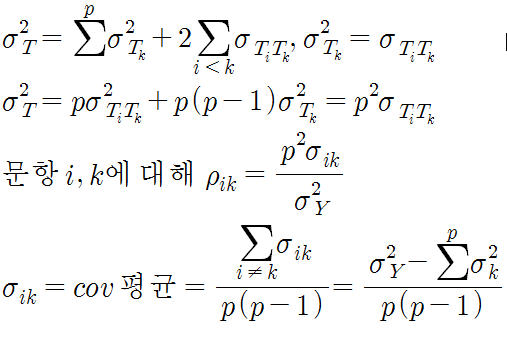
크론바하 a와 비슷한 공식으로 kuder-richardson 20이 있다. kuder-richardson 20 공식은 다음과 같다.
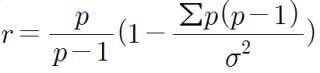
variance components analysis approach는 ANOVA 모델을 통해 신뢰도를 구하는 방법이다. ANOVA에서는 개인의 점수를 평균+개인의 T+I(집단변수)+ε로 표현하는데, 신뢰도에서는 집단변수가 문항효과(item effect)로 대체된다. variance components analysis approach는 모든 I를 더하면 0이 된다고 가정하는데, 이러한 접근법을 취하면 신뢰도를 다음과 같이 구할 수 있다.
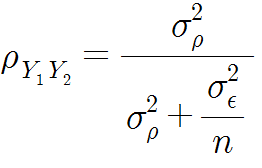
이는 다음과 같이 유도된다.

이외에 같은 검사를 앞뒤나 홀수/짝수로 항목을 둘로 나눈 후 두 검사의 점수가 비슷한지 보는 반분 신뢰도(split half reliability)나 같은 검사를 서로 다른 연구자가 채점하고 그 채점 결과를 비교하는 채점자간 신뢰도(이 신뢰도는 카파 계수를 사용한다)도 있다.
타당도의 측정
타당도는 특히 심리학의 특성상 측정이 매우 힘들기 때문에, 보통 해당 분야의 연구자 여럿이 평가하는 방식으로 평가된다. 내용 타당도(content validity)는 검사가 측정하고자 하는 구성개념을 잘 반영하는지 질적으로 평가하는 것으로 해당 분야의 전문가들이 평가한다. 안면 타당도(face validity)도 비슷하지만 안면 타당도는 검사가 구성개념의 표면적인 특징을 잘 잡아내는지를 기준으로 하는 것으로 일반인의 시각이 개입된다.
준거 타당도(criterion validity)는 가장 널리 인정받는 타당도 평가방법인데, 측정하고자 하는 대상에 대해 이미 알려진 준거(행동지표, 이전에 개발된 검사)와 얼마나 잘 맞아떨어지는지를 보는 것이다. 준거 타당도 안에서도 공인 타당도(수렴타당도)는 이전 연구자가 개발한 도구들과 상관이 강한지를 보는 것이고, 예언 타당도는 반대로 개발한 검사가 나중에 나타나는 검사나 발견되는 행동지표와 비슷한 결과를 내는지 보는 것이다. 변별타당도는 두 검사가 서로 다른 대상을 측정할때 서로 다른 정도인데, 이는 도구가 얼마나 측정대상을 가외변인과 잘 구별하는지의 정도이다.
구성 타당도(construct validity)는 요인분석과 비슷한 방법인데, 개발한 검사의 결과를 요인분석한뒤 추출된 하위개념의 구성이 이론이 예측한 것과 비슷한지 비교하는 방법이다. 이런 방법 외에도 구성 타당도와 비슷하게 검사결과가 측정하려는 대상의 구성이나 가정되는 특징과 비슷한지 보는 개념 타당도(concept validity), 검사가 측정하는 대상에 대해 최대한 많은 정보를 예측하는지 보는 증가분 타당도(incremental validity)도 있다.
- Robins, R. W., Fraley, R. C., & Krueger, R. F. (Eds.). (2009). Handbook of research methods in personality psychology. Guilford Press [본문으로]
'지식사전 > 심리학' 카테고리의 다른 글
| 지능연구 총론 (0) | 2023.01.18 |
|---|---|
| 행동주의 학습(행동학습) 정리 (0) | 2023.01.18 |
| 성범죄에 대한 연구들 (0) | 2022.12.26 |
| 집행기능 연구 정리 (1) | 2022.12.20 |
| 성차의 심리학 정리 (0) | 2022.11.23 |


