
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 일주율
- 외측 슬상핵
- sexdifference
- 켈트 매듭
- 행동주의
- individualism
- 시교차
- 시각처리
- #정신역동
- 빅토리아 시대
- #크립키
- ctm
- 연결주의
- #산업및조직심리학
- 따뜻함주의
- 강화
- 행동주의 치료
- memory
- 집단주의
- behavior modification
- 개인주의
- celtic knot
- #정신분석
- 테스토스테론렉스
- Psychology
- 심리학
- collectivism
- persuation
- 도덕발달단계론
- heartism
- Today
- Total
지식저장고
행동주의 학습(행동학습) 정리 본문
행동학습은 고전적 조건형성과 조작적 조건형성처럼 다른 학습의 기본이 되면서 행동주의자들에 의해 일찍이 연구되어온 여러 학습메커니즘을 합쳐 이르는 말로, 일반적으로 잘 사용되지 않는다. 또한 그 원리와 세부사항에 대한 지식도 행동주의자들에 의해 대부분 축적되어 다른 분야에 비해 활발한 연구가 이루어지진 않는다. 그러나 그만큼 행동학습은 심리학의 기본이며, 그래서 많은 교재에서 행동학습에 대해 기초적인 부분을 수록한다.
이 분야의 주요 연구자로는 버러스 스키너(skinner), 시겔(siegel)이 있다. 스키너는 행동주의의 거두이다.
1.개요1
행동학습은 대개 무의식적으로 일어나는 암묵 학습(implicit learning)으로,2 시행착오를 거쳐 일어난다. 손다이크가 관찰한 바에 따르면 동물이 여러 번 문제를 해결할수록 문제를 푸는데 걸리는 시간이 계속 감소했다. 이는 시행착오가 반복되면서 동물이 자극과 반응의 관계(reinforcement contingency, 강화 유관성)를 학습했기 때문이다. 행동학습은 크게 고전적 조건형성(classical conditioning, 고전적 조건화)과 조작적 조건형성(operant conditioning, 조작적 조건화, 도구적 조건형성)으로 나뉜다. 이 둘은 자극(S)과 반응(R)의 관계에 대한 학습이기 때문에 연합학습(associative learning)이라 부르는데, 연합학습과 달리 S-R 반응과 관계없이 일어나는 비연합학습도 존재한다.
연합학습은 다음의 법칙을 따른다. 손다이크는 효과의 법칙이 맨 아래의 두 법칙에 의해 보완된다고 했다. 연합학습은 연합되는 자극외에도 상황이 선행자극으로서 주요 변수로 작용하기 때문에, 특정 맥락이 아닌 곳에서 S를 가하면 R이 나타나지 않을수도 있다.
- 준비성의 법칙(law of readiness): 목표를 추구하는 행동이 방해받거나, 원하지 않는 행동을 강요받을때 동물은 좌절한다. 모든 동물은 원하는 목표를 위해 행동하기를 원한다.
- 인접의 법칙(신근의 법칙): S와 R의 시간간격이 짧을수록 연합이 강해진다. 쥐의 경우 S가 제시되고 5초가 지나면 R과 연결시킬 수 없다.
고전적 조건형성은 자연적으로 설정된 S-R 반응을 통한 학습이다.3 어느 동물 종이든 종 특유의 무조건자극(US, UCS, UnConditioned Stimulus)이 존재한다. 무조건자극은 본능적으로 UR(Unconditioned Response, 무조건반응)을 일으키며 음식을 보고 달려드는 개나 여자를 보고 흥분하는 남자의 행동이 여기 해당한다. 이때 US가 제시되고 나서 특정 S를 지속적으로 제시하면 유기체는 무의식적으로 기존의 US-UR 도식을 US-특정 S-UR로 수정하게 되어 해당 S만 제시돼도 UR이 나타난다.(이러면 이 자극을 CS, 길게 말하면 Conditioned Stimulus라 한다) 파블로프의 개로 예시를 들면 개는 음식(US)을 보면 반사적으로 침을 흘린다.(UR) 이때 개에게 음식을 주면서 지속적으로 밥을 주기 전 종(CS)을 울리면 개는 음식->침 이란 도식을 음식->종->침 이란 도식으로 수정한다. 이렇게 되면 개에게 단순히 종(CS)만 울려줘도 침(UR)을 흘리게 된다. 이때 CS에 의해 유발된 UR은 CR(Contidioned Response)라 불린다.
조작적 조건형성은 고전적 조건형성과 달리 직접 도식을 만든다. 모든 동물은 이득이 되는 행동은 더하고 해가 되는 행동은 덜하는 본능이 있다. 동물은 이득을 봤을때 보이는 확인반응에서 피드백을 받아 이를 조절하는데 조작적 조건형성은 이를 이용한다. 양갈래로 갈리는 미로에 놓인 쥐를 예로 들어보자. 쥐가 왼쪽 미로로 갔을때 음식을 주면 쥐는 왼쪽 미로로 가는 행동이 이득임을 알게 된다. 그러면 음식을 위해 왼쪽 미로로 가는 행동이 증가한다. 반대로 쥐가 오른쪽 미로로 갔을때 전기충격이 가해진다고 하자. 그러면 쥐는 오른쪽 미로로 가는 행동이 해로움을 알게 되어 오른쪽으로 가는 행동이 감소한다. 조작적 조건형성은 이처럼 동물이 강화(reinforcement)받는 행동은 늘리고 처벌(punishment)받는 행동은 감소시키는 경우를 말한다. 조작적 조건화는 동물이 보상을 위해 자발적으로 하는 행동을 유발한다.
연합학습은 연합이 약해지면 소거(extinction)가 일어날 수 있다. 소거는 이전에 학습한 행동이 연합이 더이상 제공되지 않으면 사라지는 현상을 말한다. 고전적 조건화의 경우 CS가 US와 연결되지 않으면 소거가 일어난다. 조작적 조건화에서는 학습한 행동이 더이상 강화되지 않으면 소거가 일어난다. 동물들은 소거가 일어나면, 학습한 행동이 급격히 증가하다 감소하는 현상을 보이기도 한다.(소거폭발, 소거발작. 신기하게 고전적 조건화된 상황에서는 나타나지 않는다) 그러나 사실 소거된 행동은 가끔씩 자발적으로 나타날 수 있고, 연합이 다시 시작되면 학습 이전보다 더 빠르게 재학습한다. 이를 자발적 회복(spontaneous recovery)이라 부르며, 동물이 소거된 행동도 일종의 기저선율(baseline rate)을 우연보다 높게 유지하기 때문에 일어난다. 이는 소거가 완전한 학습의 소멸이 아닌 행동의 억제일 뿐이라는 사실을 보여준다.

또한 연합학습은 의도하지 않았던 다른 행동을 학습시킬수도 있다. Generalization(stimulus generalization, 일반화, 자극 일반화)는 자극-반응 연합을 학습시켰을때 반응이 학습시킨 자극 외의 다른 자극이 주어질 때도 나타나는 현상을 말한다. 종소리가 들린 후 먹이를 주는 고전적 조건형성 이후에 딸랑이 소리만 들어도 침을 흘리는 경우가 일반화의 예이다. 반대로 Discrimination(stimulus discrimination, 변별화, 자극 변별)는 여러 번의 학습을 통해 특정 자극만 분리해서 반응하는 현상이다. 비둘기에게 여러 그림을 보여주고 모네 풍 그림을 부리로 쪼아야 먹이를 얻도록 학습시키면 비둘기는 나중에 모네의 그림을 피카소의 그림과 구분할수 있다.4 사실 대부분의 학습은 변별되는 자극에 대하여 일어난다.(자극제어, 자극통제, stimulus control) 변별화는 학습을 여러번 할수록 잘 일어나며 특정 자극에만 차별적 강화를 받을때 일어난다.
일반화가 일어나는 양상은 일반화 쏠림을 따른다. Generalization gradient(일반화 쏠림, 일반화 변화도)은 어떤 자극이 연합된 자극과 유사할수록 반응이 발생할 확률이 높아지는 현상을 말한다. 일반화가 일어나면 연합된 자극과 유사한 자극들에서도 약하지만 동일한 반응이 나타나는데,5 보통 물리적으로 유사한 자극에서 일반화가 잘 일어난다.6 인류학의 sympathetic magic(공감주술)은 서로 비슷한 사물이거나 한번 인접한 사물은 서로 연결되어 있다는 믿음과 이에 기반한 주술인데, 이는 서로 연합된 자극과 그것이 generalization된 자극에 대한 무의식적 인지의 반영이라고 할 수 있다.7
하지만 학습을 통해서 개념적으로 비슷한 자극(이 경우 보통 유사한 물리적 속성stimulus class를 공유한다)을 서로 비슷한 것으로 간주하도록 학습할 수 있는데, 이러한 경우 개념적으로 유사한 자극에도 일반화가 일어날 수 있다. 한편 유사 자극에 대해 일어나는 일반화는 자극일반화라 하지만, 동일한 반응이 여러 자극에 걸쳐 나타나는 경우에는 반응일반화라고 한다.
연합학습은 기본적으로 대뇌보다는 더 하위의 기관이 관여한다. 한 예로 여러 연구에 따르면 소뇌가 이러한 연합학습이 형성되는데 긴밀히 관여한다.8
2.고전적 조건화9
Classical conditioning(pavlovian conditioning, 고전적 조건화, 고전적 조건형성, 파블로프적 조건화, 반응적 조건화)는 자연적으로 설정된 S-R 반응을 통한 학습이다.10 어느 동물 종이든 종 특유의 무조건자극(US)이 존재한다. 무조건자극은 본능적으로 무조건반응(UR)을 일으키며 음식을 보고 달려드는 개나 여자를 보고 흥분하는 남자의 행동이 여기 해당한다. 이때 US가 제시되고 나서 짧은 기간 안에 특정 S를 지속적으로 제시하면 유기체는 무의식적으로 기존의 US-UR 도식을 US-특정 S-UR로 수정하게 되어 해당 S만 제시돼도 UR이 나타난다.(이러면 이 자극을 CS라 한다) 파블로프의 개로 예시를 들면 개는 음식(US)을 보면 반사적으로 침을 흘린다.(UR) 이때 개에게 음식을 주면서 지속적으로 밥을 주기 전 종(CS)을 울리면 개는 음식->침 이란 도식을 음식->종->침 이란 도식으로 수정한다. 이렇게 되면 개에게 단순히 종(CS)만 울려줘도 침(UR)을 흘리게 된다. 이때 CS에 의해 유발된 UR은 CR(Contidioned Response)라 불린다.
고전적 조건화를 이해하려면 몇가지 개념을 이해해야 한다. 획득(acquisition)은 CS와 US가 연합되는 기간이다. 고전적 조건형성이 발생하기 위해서는 획득 기간이 반드시 필요하다. CS에 의한 반응빈도를 그래프로 나타내면 0에 가까웠던 반응이 획득 기간 동안 급격히 상승하는 것을 볼 수 있을 것이다. 2차 조건형성(second-order conditioning)은 CS를 일종의 시드로 사용하여 다른 고전적 조건화를 형성하는 것으로, 여기서는 이전에 학습된 CS가 US의 역할을 한다.
특정 S가 어느 시점에 나타나는지도 고전적 조건형성에 영향을 준다. 가장 좋은 경우는 S가 US 이전에 일어나는 것으로(지연조건형성, delay conditioning) 이런 경우에 고전적 조건화가 가장 확실하게 일어난다. S가 US가 발생하기 좀 오래전에 발생하는 경우를 흔적조건형성(trace conditioning)이라 하는데, S가 발생한 시점과 US가 발생한 시점의 정도가 크면 클수록 학습이 이뤄지기 힘들다.11
S가 US와 동시에 일어나거나 후에 일어나는 경우를 각각 동시조건형성(simultaneous conditioning), 후진조건형성(backward conditioning, 역향 조건형성)이라 하는데, 동시조건형성은 학습을 일으키지 못하고, 후진조건형성은 지연조건형성과 다른 방식으로 학습이 일어난다. 예를 들어 US가 전기충격처럼 연속적으로 일어날 수 있는 S면, US 이후에 일어난 S는 US가 끝났다는 신호로 해석되어 UR과는 다른 CR을 일으킨다. 실제로 전기충격을 US로 제시하고 CS를 US의 전/후에 제시한 실험에서 US 발생 전에 CS를 제시한 집단은 CS 이후 회피행동이 늘어났지만 후자의 집단은 CS 이후 오히려 회피행동이 줄어들었다.
고전적 조건화는 주로 소뇌가 연관된다.12 이러한 연구는 대개 토끼를 대상으로 실시되었으나 뇌손상 환자에 대한 연구도 같은 결과를 보여준다.13 흔적 조건형성의 경우 해마에서도 일부 관여하나 지연 조건형성에서는 그렇지 않다.14 한편 공포에 대한 고전적 조건화(공포학습)의 경우에는 편도체도 여기 관여한다.15
레스콜라-와그너 모형(rescorla-wagner model)16
지금까지 고전적 조건화는 비인지적 학습으로 여겨졌고, 실제로도 일부 그렇다. 그러나 현대 학자들의 연구결과 고전적 조건화에도 인지적 요소가 상당히 개입되는 것으로 밝혀졌다. 특히 기대와 변별은 고전적 조건화가 일어나는데 관여하는 핵심 요소이다. 레스콜라와 와그너는 이를 종합하여 1972년 고전적 조건화를 설명하는 레스콜라-와그너 모형(레스콜라-바그너 모형)을 구축하였다.
레스콜라-와그너 모형에 따르면 고전적 조건화가 일어나기 위해서는 동물이 대상에 주의를 기울여야 한다. 파블로프의 개를 예로 들어보자. 파블로프의 개는 종소리에는 반응했지만 연구자에는 반응하지 않았다. 이는 이상한 일이다. 왜냐하면 결국 먹이를 넣어주는것도 연구자고, 연구자 출현이라는 자극도 먹이라는 US와 연결되기 때문이다. 그러나 개는 종소리가 먹이 US와 바로 결합되는 것과 달리, 연구자 출현 자극은 실험기구 점검, 개 쳐다보기, 눈금 바라보기 등 다른 다양한 자극과 연결된다는 것을 알고 있었다. 그렇기 때문에 연구자 출현이 무엇과 연합되는지는 모호한 반면, 종소리는 먹이와 연결된다고 기대할 수 있었다. 그리고 종소리-먹이라는 연결은 이러한 기대 속에서 가능했다.17 사실 개는 다른 정보보다 청각정보에 주의를 더 기울이는 경향이 있다.18
이는 다음과 같은 사실을 예견한다. 고전적 조건화는 CS가 친숙하지 않은 자극일때 더 일어나기 쉽다. 왜냐하면 친숙한 자극은 이미 다른 US와 연결되어 있어 기대를 부르기 쉽지 않기 때문이다. 그러나 US가 이미 다른 CS와 강하게 연결된 경우, 새로운 CS에는 주의가 기울여지지 않아 학습이 일어나기 어렵다.19 여기에는 인지적인 요소, 즉 생각하는 능력이 필요하다. 그렇다면 비슷하게 고전적 조건화에도 의식적 요인이 개입한다고 주장할 수도 있을 것이다. 이는 기존 학자들의 반발에 부딫혔으나20 기억상실증 환자에 대한 연구가 축적되면서 뒤집어졌다. 진행성 기억상실의 경우 외현기억(의식적 정보처리)은 더이상 저장할 수 없지만 암묵기억(무의식적 정보처리)은 그렇지 않다. 그렇기 때문에 고전적 조건화를 통한 학습이 가능하다. 그러나 연구결과 진행성 기억상실증 환자들은 흔적 조건형성은 학습에 실패했다.21 이는 흔적 조건형성의 경우 시간 간격으로 떨어진 두 사건을 이으려면, 두 사건이 연결되어 있다는 자각이 필요하기 때문으로 보인다.22
한편 흔적 조건형성 여부를 통해 의식의 존재를 파악하는 절차는 식물인간에게 의식이 있는지 파악하는 데에도 사용되었다. bekinschtein과 동료들23은 과연 식물인간이 무언가를 자각할 만큼의 의식이 있는지 알아보기 위해 22명의 식물인간에게 흔적 조건형성을 실시하였다. 그리고 이들의 반응을 마취제를 통해 혼수상태에 놓인 대조군의 반응과 비교하였다. 그 결과 식물인간은 확실한 흔적 조건형성을 보였다. 이것이 의식적 처리 없이 일어나는 흔적 조건형성때문에 그러할 가능성도 약간 있지만, 합리적으로 이는 식물인간에게 의식이 있다는 증거로 해석된다.
이 분야의 주요 연구자로는 로버트 레스콜라(rescorla)와 앨런 와그너(wagner)가 있다. 레스콜라와 와그너는 레스콜라-와그너 모형을 창안했다.
3.조작적 조건화24
조작적 조건형성(조작적 조건화)은 동물이 주어지거나 제거된 자극에 따라 다르게 행동하는 경우로, 유기체가 자기 행동의 결과에 따라 미래에 그 행동을 할지를 결정하는것과 관련된 학습을 말한다. 모든 동물은 이득이 되는 행동은 더하고 해가 되는 행동은 덜하는 본능이 있는데 이를 효과의 법칙(law of effect)라 한다. 동물은 이득을 봤을때 보이는 확인반응에서 피드백을 받아 이를 조절하는데 조작적 조건형성은 이를 이용한다. 조작적 조건형성은 동물이 강화(reinforcement)받는 행동은 늘리고 처벌(punishment)받는 행동은 감소시키는 경우를 말한다. 그리고 강화학습을 일으킨 자극을 강화인(reinforcer)이라 하며, 강화인이 행동을 증가시키면 강화물(reinforcer)이라 하고 행동을 감소시키면(즉 처벌로 작동하면) 이를 처벌물(punisher)이라 한다.. 강화인은 특정 역치를 넘는지에 따라 평가되는 가치가 달라진다.
조작적 조건화를 흔히 도구적 조건화라고 한다. 사실 이 둘은 결과적으로 같지만 엄밀히 말하면 둘은 다른 개념이다. 도구적 조건화는 도구적 목적의 행동이 형성되는 조건화이다. 그래서 도구적 조건화를 연구하는 학자들은 피험체가 특정 문제를 어떻게 해결하는지에 연구중점을 둔다. 고양이가 어떻게 문제상자를 빠져나오는지 측정한 손다이크의 연구가 대표적인 도구적 조건화에 대한 연구다. 반면 조작적 조건화는 굳이 도구적 행동을 찾을 필요가 없다. 어떤 문제를 해결하는지와 상관없이 그냥 특정 자극의 획득/제거 이후에 행동이 변화하면 이는 조작적 조건화에 들어간다. 그래서 조작적 조건화를 연구하는 학자들은 형성된 행동의 반응비율, 반응시간을 측정한다. 하지만 도구적 조건화를 굳이 조작적 조건화와 따로 떼어 논할 이유가 별로 없기 때문에 보통 도구적 조건화를 조작적 조건화와 동일시한다.
조작적 조건화는 심리학자 스키너가 스키너 박스(skinner box, 스키너 상자)를 통해 행동을 연구하면서 체계화되었다. 스키너 박스의 구조는 다음과 같다.
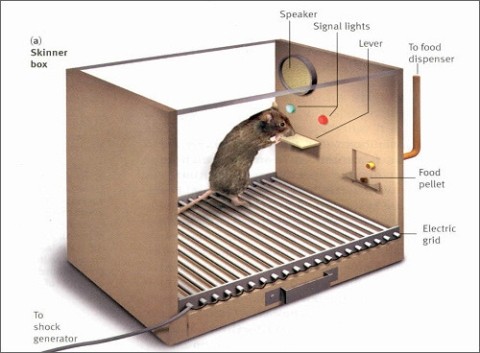
스키너 박스에 들어가는 쥐는 보통 오랫동안 먹이를 먹지 못한 상태이다. 그렇기 때문에 박탈시간이 길어 허기가 충만해있다. 이런 쥐가 박스에 들어간 후 우연히 레버(lever)를 누르면 먹이구멍(food pellet)에서 먹이가 나온다. 배고픈 쥐에게 먹이는 충분히 이득이다. 이러한 우연이 몇 번 반복되면 쥐는 레버를 누르면 먹이가 나온다는 사실을 학습하게 되고 이후 배고플 때마다 레버를 누르게 된다. 다르게 표현하면 레버를 누르는 행동을 했을때 먹이라는 자극이 주어지면 쥐의 레버 누르기 행동이 증가한다. 이 행동은 그래프에 누적적으로 기록되고 그래프는 시간에 따라 증가하는 쥐의 레버 누르기를 표시한다. 스키너는 스키너 박스에 쥐 이외에도 비둘기, 고양이 등 사람빼고 정말 다양한 동물을 넣었다.
강화와 처벌
강화는 행동을 늘리는 기제이고 처벌은 행동을 줄이는 기제이다. 만약 어떤 자극을 유기체에게 제공했을때 유기체의 행동이 증가한다면 강화이고, 감소한다면 처벌이다. 강화를 일으키는 자극은 보상, 처벌을 일으키는 자극을 혐오자극이라 한다. 여기서 S가 주어지는 형태에 따라서도 강화와 처벌을 분류할 수 있는데, 어떤 S가 제거되는 경우에는 부적, 어떤 자극이 가해지는 경우에는 정적이라 한다. 이렇게 조작적 조건화는 정/부적 차원까지 고려하여 정적 강화, 부적 강화, 정적 처벌, 부적 처벌로 나눌 수 있다. 예를 들어 유기체에게 가해지는 어떤 자극을 제거했더니 유기체의 행동이 늘어났다면 이 조작은 부적 강화이다. 제거되는 자극이 돈이라서 도저히 강화로 보기 힘들더라도 유기체의 행동이 늘어난다면 이는 강화이다. 사실 강화인은 개인마다, 상황마다, 시간마다 다르고 상황과 개인에 가장 맞는 강화인이 가장 큰 강화를 일으킨다.
강화는 위에서 말했듯이 자극이 더해지는지 제거되는지에 따라 정적 강화(positive reinforcement)와 부적 강화(negative reinforcement)로 나눌 수 있다. 정적 강화는 특정 행동을 한 이후에 보상 자극이 추가되는 경우로, 보상으로 주어지는 자극은 대개 생물학적으로 프로그램되었거나 이차적 강화된(심화 참조) 자극이다. 일을 한 대가로 주는 월급은 대표적인 정적 강화이다. 부적 강화는 반대로 특정 행동을 한 이후에 혐오자극이 제거되는 경우이다. 아동을 때리는 체벌자는 아이의 떼쓰는 행동이 단기간에 멈추는 걸 보고 부적 강화를 얻는다.(이를 처벌의 늪이라 한다) 보통 대부분의 조작적 조건화는 강화를 통해 이뤄지는데, 이는 그것이 더 효과적이기 때문이다. 강화는 강화인이 즉각적으로 주어질때, S-R 관계에서 혼합변수가 적을때, 강화인 자체의 유인력이 클때, 강화인의 강도(양과 세기)가 강할때 효과가 커지며, 개인차 역시 존재한다.
처벌도 비슷하게 정적 처벌(positive punishment, 수여성 처벌)과 부적 처벌(negative punishment, 제거성 처벌)로 나뉜다. 정적 처벌은 특정 행동을 한 후에 혐오자극이 추가되는 경우이다. 시험성적이 안나온다고 줄빠따를 치는 일은 정적 처벌이다. 부적 처벌은 특정 행동을 한 후에 보상이 제거되는 경우이다. 교통법규를 위반하여 벌금을 떼는 일이 대표적인 부적 처벌이다. 다른 말로 처벌은 도피를 회피로 바꾸는 일이다. 심리학에서 도피는 주어진 혐오자극을 피하는 행동을 말하고 회피는 혐오자극이 오기 전에 미리 예방하는 행동이다. 처벌을 통해 학습한 동물은 도피 상황에 처하기 전에 회피를 통해 혐오자극을 피할 수 있다.
하지만 처벌은 강화에 비해 효과가 많이 떨어진다.25 처벌은 단지 행동을 단기적으로 억제할 뿐이라 지속적인 처벌이 주어지지 않으면 행동이 기저선율로 돌아가버린다. 게다가 한번 처벌이 주어진 경우, 처벌이 주어지지 않는 상태가 하나의 자극으로 취급되어, 다음에 처벌이 주어지지 않으면 해당 행동이 부적 강화될 수 있다. 이외에도 처벌은 안좋은 정서적 부산물을 유발할 수 있고, 타인에 대한 공격성을 유발하며, 때로는 처벌된 행동이 아직 처벌되지 않은 다른 안좋은 행동으로 바뀌어 나타나기도 한다. 또한 처벌은 동물이 무엇을 해야 할지에 대한 정보는 주지 않기 때문에 강화보다 효과가 떨어진다.
처벌에 대한 사람들의 선호는 불행히도 대개 처벌의 단기적 효과와 인간 마음에 내재된 공격성에 의해 일어난다. 이들은 처벌을 통한 단기적 복종에 부적 강화되어 나중에 더 심한 처벌을 가하는 처벌의 늪에 빠질수 있기 때문에 각별히 주의해야 한다. 특히 그중 체벌은 효과는 미미한 반면 반사회적 행동을 늘리는 등26 부작용이 많기 때문에 되도록 하지 않는 편이 좋다.27
그렇다고 처벌을 쓰지 않고 강화만을 사용하기도 힘들 것이다. 처벌은 강화와 적절히 결합된 상태에서 사용되어야 효과적으로 사용될 수 있다. 처벌을 할 경우엔 부적 강화가 일어나지 않도록 항상 즉각적이고 모든 처벌대상인 행동을 처벌해야 하고, 습관화가 일어나지 않기 위해 처음부터 강한 처벌을 해야 한다. 또한 처벌을 할 때 적절한 대안행동을 제시하고 대안행동을 강화하면 효과적으로 부적절한 행동을 없앨 수 있다. 만약 자녀교육 상황이라면, 이러한 모든 것들이 부모와 자녀의 적절한 관계 속에서 도덕적 추론과 공감 교육, 모델링이 병행된다면 더 큰 효과를 거둘 수 있다.
강화인이 정확히 무슨 일을 하는지는 여러 설명이 있다. 부적 강화의 경우, 추동을 감소시키고 동시에 불안과 같은 부정적인 각성도 감소시킨다. 정적 강화의 경우에는 뇌에 유쾌한 자극을 만들어내 행동을 보상한다. 유쾌한 자극은 보상회로를 타고 올라가 뇌에 쾌락을 제공하고 긍정적인 각성을 증가시킨다. 아니면 즐거운 행동을 할 기회를 줌으로써 간접적으로 보상할수도 있는데, 평소에 잘 안하는 저빈도 행동을 하면 평소에 많이 하는 고빈도 행동을 할 기회를 주어 저빈도 행동을 늘리는 법칙을 프리맥 원리(premack principle)라 한다.28 이러한 보상은 강화인이 제공되지 않는 경우에도 강화된 행동을 얼마간 지속하게 만든다. 보상회로가 어떻게 뇌에 보상하는지는 동기연구를 참고하라.
조작적 조건화 심화29
조작적 조건화는 좀 더 복잡하게 조직됨으로서 고전적 조건화보다 더 복잡한 행동도 만들수 있다. 그 중 하나는 이차적 강화(조건화된 강화, 파생된 강화)이다. 이차적 강화는 보상과 관계없는 자극이 보상과 연결된 다른 자극과 연결되어 발생하는 강화이다. 쉽게 말해 돈은 우리에게 직접적인 보상이 아니지만, 돈이 음식, 옷, 집 등 보상과 연결되어 있기 때문에 우리는 돈을 받는 행동을 학습한다. 변별적 조작(discriminative stimulus)이 일어나는 경우에도 이차적 강화가 일어난다. 변별적 조작은 특정 맥락에서만, 실험적으로 말하면 특정 자극이 주어질 때만 행동과 자극이 연결되도록 하는 조작이다. 스키너 박스의 예를 들면 박스 안의 광원(signal lights)에 빛이 들어올때만 레버 장치가 작동하게 한다면 이를 학습한 쥐는 빛이 들어올 때만 레버를 누르게 되는데 이를 변별적 조작이라 하고, 이때 빛 자극은 보상을 간접적으로 제공하기 때문에 이차적 강화를 일으킨다.
이차적 강화에서의 강화인은 조건 강화인이라고도 한다. 이는 사후에 학습되지 않아도 본능적으로 강화인으로 작용하는 무조건 강화인과 대비된다. 그리고 돈이나 권력처럼 다양한 강화인들과 연결된 이차적 강화인은 일반화된 강화인(generalized reinforcer)이라 부른다. 그리고 이차적 강화에 의해 행동이 복잡하게 연결될때 특정 행동이 여러 이차적 강화를 경유하여 보상을 제공하는 현상을 연쇄(chaning)라 한다. 행동주의자들은 무한한 연쇄를 통해 복잡한 행동을 충분히 학습할 수 있다고 주장했지만 실제로 연합학습만으로는 3차 이상의 이차적 강화는 어렵다. 이외에 강화인이 물리적 조작으로 통해 주어지는 경우에는 자동적 강화, 사람의 행동을 통해 주어지는 경우에는 사회적 강화라고 한다.
이차적 강화를 복잡하게 엮으면 복잡한 행동을 만들수 있다. 사람들은 어떻게 돼지가 전화를 받고, 돌고래가 링을 통과하고, 침팬지가 수화를 하게 만들까? 복잡한 행동을 조건화하기 위해 쓰이는 방법을 조형(shaping, 조성, 계속적 근사법, 행동조성법)이라 한다. 조형은 목표하는 행동에 가까운 행동을 할때마다 지속적으로 강화해주는 방법이다. 만약 돌고래가 링을 통과하게 만들고 싶다면 조형은 이런 방식으로 쓰인다. 먼저 돌고래가 물 밖으로 뛰어오를 때마다 먹이를 준다. 그리고 돌고래가 물 밖으로 뛰는 행동을 학습하면 이번엔 비슷하지만 목표 행동과 더 가까운 행동, 이를테면 조련사의 손에 부딫히는 행동을 강화한다. 지속적으로 강화해주면 결국 돌고래는 링을 통과하는 행동을 학습할 수 있게 된다. 조형은 돌고래 뿐만 아니라 각종 서커스는 물론이고 견공교육이나 정신지체아, 자폐아 교육에도 사용된다.
조작적 조건화는 보통 동물에게 이득을 주지만 간혹 동물이 득이 되지 않는 행동을 하는 경우도 있다. 미신적 행동(superstitious behavior, 미신 행동)은 실제로 보상과 무관한 강화인에 의해 강화가 일어나는 현상이다. 잘 알려진 비둘기 실험에서 스키너는 비둘기를 스키너 박스에 넣고 먹이가 무작위로 나오도록 시스템했다. 그러자 비둘기들은 각자 다른 행동을 학습하여 먹이가 나올때까지 그 의미없는 행동을 반복하였다. 이는 비둘기들이 자발적으로 한 행동중에 어떤 행동이 우연히 먹이가 나오는 상황과 동시에 일어났고, 비둘기가 그 행동을 먹이를 가져다주는 행동으로 착각했기 때문에 일어난다.30 미신 행동은 인간에게도 많이 일어나는데,31 징크스에 따라 행동하는 스포츠인이나 어떤 무당이 용하다는 주장도 미신적 행동에 속한다. 미신적 행동은 도박장에서 가장 잘 찾아볼 수 있다.
도피행동(escape behavior, escape conditioning, 도피 학습)과 회피행동(avoidance behavior, avoidance conditioning, 회피 학습)은 학습심리학에서 구분된다. 도피와 회피는 둘다 부적 자극에 대한 반응인데, 도피행동은 부적 자극을 종결시키는(그것을 없애든 거기서 피하든) 행동이고, 회피행동은 부적 자극의 출현을 사전에 방지하는 행동이다. 가령 어떤 동굴에 독사가 살고 있을때, 산책 도중에 뱀을 만나 자리를 피하는 것은 도피행동이고, 아예 동굴을 막아버리는 것은 회피행동이다. 도피행동은 조작적 조건화의 결과이지만, 회피행동이 조작적 조건화의 결과인지는 논쟁이 있다. 2과정 이론에서는 회피행동이 혐오 자극에 공포 감정이 연합되고(고전적 조건화) 공포 자체가 부적 자극이 되어 이에 기반하여 조작적 조건화되는 행동이라고 주장하나, 1과정 이론에서는 혐오자극이 감소하리라는 기대 자체가 강화인으로 기능하는 조작적 조건화 상황이라고 주장한다.
조작적 조건화는 보상회로에 의해 일어난다. 어떤 행동을 한 후에 보상을 받으면, 이 보상은 보상회로를 자극하여 도파민을 분비하고, 이 도파민이 긍정적인 정서를 유발하는 동시에 긍정적 정서와 해당 행동을 연결한다. 이것이 이뤄지거나 여러번 반복되면 조작적 조건형성이 설정된다.
강화스케줄32
초기 조작적 조건화 실험은 레버를 누를 때마다 먹이를 주었다. 이처럼 행동을 할때마다 즉각적으로 강화가 되는 경우를 계속적 강화(Continuous ReinForcement, CRF, 연속강화)라 한다. 그러나 계속적 강화는 스키너의 사료예산을 예상보다 빨리 바닥나게 만들었다. 비슷하게 회사 사장님들도 매일 직원들에게 임금을 준다면 재정적으로 부담이 될 것이다. 게다가 계속적 강화는 강화인이 사라지면 매우 빠르게 소거되기 때문에 더욱 부담이 된다.
강화스케줄(강화계획)은 특정 간격을 두고 행동을 보상하는 방법이다.33 강화스케줄은 부분강화효과(partial reinforcement effect, intermittent reinforcement effect, 간헐적 강화 효과)에 기반했는데 부분강화효과에 따르면 모든 행동이 아니라 몇몇 행동에만 부분적으로 강화할 경우(간헐적 강화, intermittent reinforcement) 당장 강화인이 없어져도 비교적 더 길게 행동이 유지된다. 이는 간헐적 강화가 일어나는 경우 유기체가 소거 시점과 그렇지 않은 시점을 구분하기 어렵기 때문이다.
강화스케줄은 간격이 시간적 간격인지 행동 횟수인지, 간격이 고정되어 있는지 약간의 변동이 있는지에 따라 4가지로 나뉜다. 고정간격 계획(fixed interval schedule, FI)은 목표 행동을 계속 하면 특정 시간대마다 강화해준다. 한달 내내 일하면 특정일에 월급을 주는 회사들은 고정간격 계획에 따라 직원에게 보상하고 있다. 변동간격 계획(variable interval schedule, VI)은 특정 시간대마다 강화하되, 약간의 변동을 준다. 가령 한달에 한번 강화한다면 어떤 경우엔 20일만에, 어떤 경우엔 40일만에 강화하여 평균만 한달로 맞추는 식이다. 어떻게 보면 낚시도 변동간격 계획에 부합한다. FI와 VI는 강화가 반응과는 무관한 시간 경과를 따르기 때문에 느리고 질서정연한 반응을 산출하는 경향이 있다. 이중 FI는 강화가 주어지는 직전 시점에 행동이 증가하는 현상이 나타나는데, 특히 시간관념이 명확한 인간에게서 그러한 현상이 잘 나타난다.
고정비율 계획(Fixed RAtio schedule, FR)은 특정 횟수만큼 행동을 하면 강화해준다. 특정 갯수만큼 완성품을 만들어야 돈이 나오는 부업은 고정비율 계획의 일환이고, 극단적으로 계속적 강화도 1회마다 강화되는 고정비율 계획으로 볼 수 있다. 변동비율 계획(Variable Ratio schedule)은 역시 특정 횟수마다 강화하되 약간의 변동을 둔다. 50% 확률의 도박에 여러번 베팅하는 경우가 변동비율 계획에 속하며, 사실 대부분의 도박이 약간의 변동에서는 벗어나지만 기본적으로 변동비율 계획을 이용하고 있다. 이상 소개된 강화스케줄은 각기 다른 방식으로 행동을 증가시키는데, 아래 이미지가 이를 제시하고 있다.
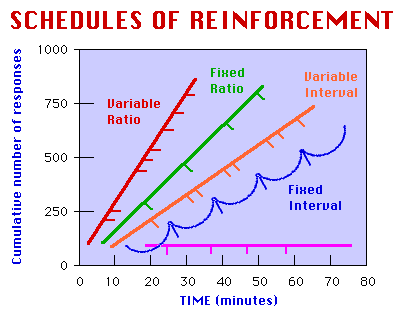
보통 비율계획이 간격계획보다 효과가 강하다. 간격 계획은 행동과 보상이 연결이 분명하지 않은데 비해 비율 계획은 횟수를 통해 행동이 보상과 명확하게 연결되기 때문이다. 같은 이유로 미래의 먼 보상보다는 현재의 가까운 보상이 더 쉽게 학습된다. 그리고 고정계획은 강화 후 휴지 현상이 일어나기 때문에 변동계획보다 약간 약하다. 강화 후 휴지(post-reinforcement pause) 현상은 보상이 주어진 직후 행동이 감소하는 현상으로, 동물이 그간의 행동으로 피로한데다 다음 보상이 일어날 때를 예상하여 지금 힘을 비축하려 하기 때문에 일어난다. 이들을 고려하면 가장 강한 강화스케줄은 변동비율 계획이다. 불행히도 도박은 대표적인 변동비율 계획이다. 인간들은 자기가 가진 동물적인 학습원리 때문에 지금 이순간에도 강원랜드에서 돈과 시간과 인생을 탕진하고 있다.
강화스케줄은 동시에 수행되기도 한다. 공시적 강화스케줄은 한 행동을 강화하기 위해 여러 강화스케줄이 사용되는 경우다. 각 강화스케줄은 제공하는 강화도 다를 수 있다. 가령 남자 히키코모리가 바깥에 나가게 하기 위해 5회 이상 현관을 나서면 돈을 주고,(고정비율 계획) 한달에 한번 예쁜 여자가 집 앞을 지나가는 경우가 있다고 하면(변동간격 계획) 공시적 강화스케줄에 해당한다. 그러나 이 경우 강화스케줄이 히키코모리에게 도움이 되지 못할수도 있다. 사실 예쁜 여자는 히키코모리를 위해 집 앞을 지나가는게 아니기 때문에 강화하고자 하는 행동이 다르다. 여자가 요구하는게 집 밖으로 나온 히키코모리가 아니라 제대로 씻는 사람이라면 경우에 따라 우리의 잘 안씻는 히키코모리의 행동에 처벌을 가할 수 있다. Herrnstein은 이를 대응의 법칙(matching law)이라 불렀는데 이의 확장형이 밑의 공식이다.

위 공식은 여러 개의 강화스케줄이 개입되면 안좋은 효과를 가져올 수 있음을 암시한다. 저 식에서 다른 R이 증가한다면 Rx는 오히려 감소할 것이다. 그렇게 된다면 Rx와 연관된 Bx도 감소할 수 있다. 다른 행동이나 강화의 증가는 목표행동의 감소를 불러올 수 있다. 그래서 스키너는 특정 행동을 교육할때 환경을 통제해야 한다고 강조했다.
4.행동학습의 변경지대34
행동학습에 대한 기초지식은 대개 20세기 중반에 정립되었다. 당시 심리학을 지배하던 행동주의자들은 행동학습이 모든 인간행동을 설명할 수 있으며 행동이야말로 진정한 과학의 성취라 믿었다. 그러나 현시점에 이에 동의하는 이는 아무도 없다. 사실 당시에도 몇몇 학자들은 행동학습으로 설명할 수 없는 여러 현상들을 발견했다. 이 현상들은 처음에는 무시되거나 설명되지 않은 현상을 치부되었으나 이들이 쌓이고 쌓이면서 마침내 행동주의 패러다임을 뒤짚게 된다.
행동학습으로 설명되지 않는 현상 중 하나는 초기 행동주의자인 손다이크에 의해 제시되었다. 손다이크는 자신의 이론을 수정하면서 소속성(belongingness)이라는 개념을 도입했다. 소속성은 S-R이 단순히 인접하지 않아도 관계가 가까우면 학습되기 쉽다는 이론이다. 가령 1895년에 일어난 파쇼다 사건과 황성신문 창립을 같이 외우기는 조금 힘들지만, 1895년에 창간된 황성신문과 1905년에 황성신문에서 발표된 시일야방성대곡을 같이 외우기는 좀 더 쉬울 것이다. 동물의 경우로 보면 반응에 의해 유발된 효과가 동물이 지금 가진 욕구와 관련된다면 그렇지 않은 경우보다 더 빨리 학습될 것이다. 이 이론은 S-R 반응에 S나 R 말고도 개입하는 다른 내적 구조가 있음을 시사한다.
비슷한 현상이 쥐에게도 관찰된다. T자형 미로에 배치된 쥐는 한번 먹이가 한쪽 팔에 나타나면, 그 다음에는 반대쪽 팔을 먼저 찾아본다. 분명히 강화된 행동과 반대로 행동하는 이 사례는 매우 이상하게 보인다. 그러나 쥐의 진화적 환경을 고려하면 쥐의 행동이 더 합리적이다. 자연에서 계속해서 쥐의 먹이가 나타나는 곳은 없고, 먹이를 얻은 쥐는 먹이가 있는 다른 공간을 찾아보아야 한다. 즉 T자형 미로에서 쥐는 이미 한쪽 통로의 먹이는 얻었으니, 이제 다른 통로에도 먹이가 있는지 찾아보는 것이다. 이는 진화적 배경(biological constraint, 생물적 제약)이 행동학습에 영향을 끼칠 수 있으며, 또한 인지적 요소도 행동학습에 영향을 끼침을 보여준다.35
진화론과 행동(생물적 준비성)36
더 중요한 것은 Breland 부부에 의해 보고된 본능표류 현상이다. 본능표류는 동물의 행동이 본능의 틀에서 벗어나지 못하거나, 설령 벗어나는 행동을 학습하더라도 시간이 지나면 본능적인 행동으로 회귀하는 현상을 말한다. 돼지는 작고 반짝이는 물건은 땅에 파묻고 보는 본능이 있는데, 대표적인 작고 반짝이는 물건은 동전이다. Breland 부부는 수많은 노력을 들였지만 돼지가 돈을 파묻지 않고 저금하도록 만드는데 실패했다.37 이는 모든 행동이 학습의 결과는 아니며, 행동학습에도 한계가 있음을 보여준다.
이는 행동학습 기제가 진화에 도움이 되어 선택되었지만, 동시에 행동학습에 위배되는 경향성도 진화에 유리하여 선택되었기 때문에 발생한다. 어떤 학습이든 생존에 도움이 될 수 있지만, 어떤 학습은 생존에 더 도움이 될 것이고, 그런 학습은 더 빨리 형성되도록 진화적 압력이 작용할 것이다.38 가령 쥐도 어렵게 훈련시키면 자취색을 변별할 수 있겠지만, 그보다는 자취석 향을 학습시키는게 더 쉽다. 왜냐하면 쥐는 후각이 주된 감각기관이기 때문이다. 이처럼 어떤 동물이 특정 연합은 더 빨리 학습하는 현상을 garcia efffect라 하는데, 이는 각 종의 생물적 준비성(biological preparedness)이 다르기 때문이다. 생물적으로 준비된 기제는 다음과 같은 특성을 가진다.
- 빠르게 학습된다. 심하면 1-2번의 학습으로 일어난다.
- 독성물질에 대한 연합의 경우, 지연 조건형성이 용이하다. 즉 음식을 먹고 수시간 후에 고통이 와도 둘 간의 연합이 가능하다.
- 음식혐오는 음식의 냄새와 맛에 대한 혐오이다.
- 혐오학습은 새로운 대상과 더불어 더 자주 발생한다. 친숙한 대상은 쉽게 기피하지 않는다.
garcia effect는 도처에서 발견된다. taste aversion learing 연구 결과 쥐는 음식의 맛과 냄새 또는 온도39에 대해서만 혐오반응을 학습했다.40 반면 후각보다 시각이 중요한 메추라기는 색깔을 통한 혐오학습이 더 수월했다.41 환경과 학습이 매우 중요한 인간은 garcia effect가 거의 관찰되지 않는다. 그러나 어떤 부분에서 인간은 생물적 준비성을 보인다. 암 환자들은 병원식에 대한 거부감과 구토를 종종 보이는데, 이는 항암치료 전에 주는 새로운 병원식이 항암치료 자체보다 쉽게 항암치료의 불쾌감과 연합되기 때문이다. 그래서 병원식을 익숙한 음식으로 바꾸자 병원식에 대한 거부반응이 사라졌다.42
잠재학습(latent learning)43
잠재학습은 무언가가 학습되었으나 이것이 행동으로 나타나지 않는 경우를 말한다. 잠재학습은 강화가 주어지지 않아도 일어나고,44 단지 강화가 주어지기 시작하면 행동으로 나타난다. 잠재학습은 톨먼에 의해 처음 제안되었는데, 톨먼은 쥐에게 미로통과 훈련을 시키던 도중 이를 발견하였다. 실험에서 톨먼은 한 집단에는 미로를 잘 통과할때마다 강화를 제공하여 조작적 조건화를 실시하였고, 다른 집단은 그러지 않았다. 이후 두 집단 모두에게 마지막 7일동안 특정 지점에 도착하면 먹이를 먹도록 강화했는데, 그러자 학습기간의 차이에도 불구하고 두 집단은 서로 비슷한 속도로 먹이의 위치를 학습하였다.
이는 쥐가 미로가 전반적으로 어떻게 생겼는지에 대한 인지도(cognitive map)를 학습하고 있음을 보여주며, 강화에 관계없이 쥐들이 이를 알고 있었음을 보여준다. 실제로 후속연구에서는 기존에 학습되었던 경로를 막아도 쥐들은 다른 길로 돌아가 먹이를 얻었다. 이는 쥐가 환경의 물리적 특성에 대해 표상을 형성하고 있으며,45 이것이 강화와 관련없이 습득되었음을 보여준다.
- Schacter 외 2인,'심리학 입문(2)',민경환 외 8인 역,시그마프레스,p104,p222 [본문으로]
- Schacter 외 2인,'심리학 입문(2)',민경환 외 8인 역,시그마프레스,p248 [본문으로]
- Pawlow, I. P. (1923). New researches on conditioned reflexes. Science, 58(1506), 359-361. [본문으로]
- Watanabe, S., Sakamoto, J., & Wakita, M. (1995). PIGEONS'DISCRIMINATION OF PAINTINGS BY MONET AND PICASSO. Journal of the experimental analysis of behavior, 63(2), 165-174. 이 연구는 1995년 이그노벨상을 수상한다 [본문으로]
- Pearce, J. M. (1987). A model for stimulus generalization in Pavlovian conditioning. Psychological review, 94(1), 61;Rescorla, R. A. (2006). Stimulus generalization of excitation and inhibition. Quarterly Journal of Experimental Psychology, 59(1), 53-67;Siegel, S., Hearst, E., & George, N. (1968). Generalization gradients obtained from individual subjects following classical conditioning. Journal of Experimental Psychology, 78(1), 171. [본문으로]
- Siegel, S., Hearst, E., & George, N. (1968). Generalization gradients obtained from individual subjects following classical conditioning. Journal of Experimental Psychology, 78(1), 171. [본문으로]
- Rozin, P., Millman, L., & Nemeroff, C. (1986). Operation of the laws of sympathetic magic in disgust and other domains. Journal of personality and social psychology, 50(4), 703. [본문으로]
- Bellebaum, C., & Daum, I. (2011). Mechanisms of cerebellar involvement in associative learning. Cortex: A Journal Devoted to the Study of the Nervous System and Behavior;Timmann, D., Drepper, J., Frings, M., Maschke, M., Richter, S., Gerwig, M. E. E. A., & Kolb, F. P. (2010). The human cerebellum contributes to motor, emotional and cognitive associative learning. A review. Cortex, 46(7), 845-857. [본문으로]
- Schacter 외 2인,'심리학 입문(2)',민경환 외 8인 역,시그마프레스,pp218-221 [본문으로]
- Pawlow, I. P. (1923). New researches on conditioned reflexes. Science, 58(1506), 359-361. [본문으로]
- Kimble, G. A. (1947). Conditioning as a function of the time between conditioned and unconditioned stimuli. Journal of Experimental Psychology, 37(1), 1. [본문으로]
- Thompson, R. F. (2005). In search of memory traces. Annu. Rev. Psychol., 56, 1-23;Cheng, D. T., Disterhoft, J. F., Power, J. M., Ellis, D. A., & Desmond, J. E. (2008). Neural substrates underlying human delay and trace eyeblink conditioning. Proceedings of the National Academy of Sciences, 105(23), 8108-8113. [본문으로]
- Daum, I., Schugens, M. M., Ackermann, H., Lutzenberger, W., Dichgans, J., & Birbaumer, N. (1993). Classical conditioning after cerebellar lesions in humans. Behavioral neuroscience, 107(5), 748. [본문으로]
- Thompson, R. F. (2005). In search of memory traces. Annu. Rev. Psychol., 56, 1-23;Cheng, D. T., Disterhoft, J. F., Power, J. M., Ellis, D. A., & Desmond, J. E. (2008). Neural substrates underlying human delay and trace eyeblink conditioning. Proceedings of the National Academy of Sciences, 105(23), 8108-8113. [본문으로]
- LeDoux, J. E., Iwata, J., Cicchetti, P. R. D. J., & Reis, D. J. (1988). Different projections of the central amygdaloid nucleus mediate autonomic and behavioral correlates of conditioned fear. Journal of Neuroscience, 8(7), 2517-2529;Olsson, A., & Phelps, E. A. (2007). Social learning of fear. Nature neuroscience, 10(9), 1095-1102;Phelps, E. A., & LeDoux, J. E. (2005). Contributions of the amygdala to emotion processing: from animal models to human behavior. Neuron, 48(2), 175-187. [본문으로]
- Schacter 외 2인,'심리학 입문(2)',민경환 외 8인 역,2015,pp224-225 [본문으로]
- Rescorla, R. A. (1988). Pavlovian conditioning: It's not what you think it is. American psychologist, 43(3), 151;Rescorla, R. A. (1966). Predictability and number of pairings in Pavlovian fear conditioning. Psychonomic Science, 4(11), 383-384. [본문으로]
- Jenkins, H. M., Barrera, F. J., Ireland, C., & Woodside, B. (1978). Signal-centered action patterns of dogs in appetitive classical conditioning. Learning and Motivation, 9(3), 272-296. [본문으로]
- Kamin, L. J. (1967, December). Predictability, surprise, attention, and conditioning. In Symp. on punishment (No. TR-13). [본문으로]
- Eichenbaum, H. (2001). The hippocampus and declarative memory: cognitive mechanisms and neural codes. Behavioural brain research, 127(1-2), 199-207;Squire, L. R., & Kandel, E. R. (1999). Memory: From mind to molecules (Vol. 69). [본문으로]
- McGlinchey-Berroth, R., Carrillo, M. C., Gabrieli, J. D., Brawn, C. M., & Disterhoft, J. F. (1997). Impaired trace eyeblink conditioning in bilateral, medial-temporal lobe amnesia. Behavioral neuroscience, 111(5), 873. [본문으로]
- Clark, R. E., & Squire, L. R. (1998). Classical conditioning and brain systems: the role of awareness. science, 280(5360), 77-81 [본문으로]
- Bekinschtein, T. A., Shalom, D. E., Forcato, C., Herrera, M., Coleman, M. R., Manes, F. F., & Sigman, M. (2009). Classical conditioning in the vegetative and minimally conscious state. Nature neuroscience, 12(10), 1343-1349 [본문으로]
- Schacter 외 2인,'심리학 입문(2)',민경환 외 8인 역,2015,pp229-231 [본문으로]
- Schacter 외 2인,'심리학 입문(2)',민경환 외 8인 역,2015,p231,p235,p240 [본문으로]
- Mulvaney, M. K., & Mebert, C. J. (2007). Parental corporal punishment predicts behavior problems in early childhood. Journal of family psychology, 21(3), 389. [본문으로]
- Gershoff, E. T., & Bitensky, S. H. (2007). The case against corporal punishment of children: Converging evidence from social science research and international human rights law and implications for US public policy. Psychology, Public Policy, and Law, 13(4), 231. [본문으로]
- Klatt, K. P., & Morris, E. K. (2001). The Premack principle, response deprivation, and establishing operations. The Behavior Analyst, 24, 173-180. [본문으로]
- Gershoff, E. T. (2002). Corporal punishment by parents and associated child behaviors and experiences: a meta-analytic and theoretical review. Psychological bulletin, 128(4), 539. [본문으로]
- Skinner, B. F. (1948). 'Superstition'in the pigeon. Journal of experimental psychology, 38(2), 168. [본문으로]
- Mellon, R. C. (2009). Superstitious perception: Response-independent reinforcement and punishment as determinants of recurring eccentric interpretations. Behaviour research and therapy, 47(10), 868-875. [본문으로]
- Schacter 외 2인,'심리학 입문(2)',민경환 외 8인 역,2015,pp233-235 [본문으로]
- Ferster, C. B., & Skinner, B. F. (1957). Schedules of reinforcement. [본문으로]
- Schacter 외 2인,'심리학 입문(2)',민경환 외 8인 역,2015,pp227-228 [본문으로]
- Olton, D. S., & Samuelson, R. J. (1976). Remembrance of places passed: spatial memory in rats. Journal of experimental psychology: Animal behavior processes, 2(2), 97. [본문으로]
- Schacter 외 2인,'심리학 입문(2)',민경환 외 8인 역,2015,p241 [본문으로]
- Breland, K., & Breland, M. (1961). The misbehavior of organisms. American psychologist, 16(11), 681. [본문으로]
- Gallistel, C. R. (2000). The replacement of general-purpose learning models with adaptively specialized learning modules. The new cognitive neurosciences, 1179-1191. [본문으로]
- Smith, P. L., Smith, J. C., & Houpt, T. A. (2010). Interactions of temperature and taste in conditioned aversions. Physiology & behavior, 99(3), 324-333. [본문으로]
- Garcia, J., & Koelling, R. A. (1966). Relation of cue to consequence in avoidance learning. Psychonomic science, 4(1), 123-124. [본문으로]
- Wilcoxon, H. C., Dragoin, W. B., & Kral, P. A. (1971). Illness-induced aversions in rat and quail: Relative salience of visual and gustatory cues. Science, 171(3973), 826-828. [본문으로]
- Broberg, D. J., & Bernstein, I. L. (1987). Candy as a scapegoat in the prevention of food aversions in children receiving chemotherapy. Cancer, 60(9), 2344-2347. [본문으로]
- Schacter 외 2인,'심리학 입문(2)',민경환 외 8인 역,2015,p239 [본문으로]
- Tolman & Honzik(1930). "Insight" in rats. University of California Publications in Psychology, 4:215-232 [본문으로]
- Tolman, E. C., & Honzik, C. H. (1930). Introduction and removal of reward, and maze performance in rats. University of California publications in psychology;Tolman, E. C., Ritchie, B. F., & Kalish, D. (1946). Studies in spatial learning. I. Orientation and the short-cut. Journal of experimental psychology, 36(1), 13. [본문으로]
'지식사전 > 심리학' 카테고리의 다른 글
| 인지와 사회성, 도덕의 발달 (1) | 2023.02.01 |
|---|---|
| 지능연구 총론 (0) | 2023.01.18 |
| 심리측정학 총론 (0) | 2023.01.02 |
| 성범죄에 대한 연구들 (0) | 2022.12.26 |
| 집행기능 연구 정리 (1) | 2022.12.20 |

