
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- behavior modification
- 외측 슬상핵
- 개인주의
- 켈트 매듭
- 따뜻함주의
- criminal psychology
- 심리학
- Psychology
- #정신분석
- sexdifference
- 강화
- individualism
- 행동주의 치료
- celtic knot
- 집단주의
- #산업및조직심리학
- collectivism
- #정신역동
- heartism
- 일주율
- ctm
- persuation
- #크립키
- 시각처리
- 연결주의
- memory
- 행동주의
- 빅토리아 시대
- 도덕발달단계론
- 테스토스테론렉스
- Today
- Total
지식저장고
분산분석의 효과크기/사후 테스트 본문
분산분석이 다른 검정에 비해 특이한 점은 사후검정의 존재이다. 분산분석은 동시에 여러 집단을 처리하기 때문에 정작 어떤 집단이 유의미함을 만들어내는지는 알기 힘들다. 그래서 사후검정을 통해 어떤 집단이 유의미함을 만들어내는지 찾아보는 과정이 필요하다. 또한 분산분석의 효과크기는 피어슨 상관계수처럼 특정 변수의 직접적인 영향력을 알 수 있게 한다는 점도 분산분석의 특이점 중 하나다. 여기서는 분산분석의 효과크기와 사후검정에 대해 다룬다.
1.효과크기 계산
분산분석에서 효과크기는 ω^2와 η^2(eta square)로 계산한다. 자세한 건 나무위키를 참고하라. 여기서는 η^2만 기술한다. F값이 유의미한지 결정하는 것은 실질적으로 SSbetween이다. 특히 대안가설이 참일 경우 실험적 처치를 가한 집단으로 인해 SSbetween이 커지기 때문에, SSbetween이 얼마나 큰지의 여부로 실험적 처치의 효과크기를 짐작할 수 있다. 그래서 η^2는 SSbetween의 상대적인 크기를 측정하며 식은 다음과 같다.

2.Priori Comparison(Planned Cmparison)
사후검정은 실행시기에 따라 priori와 post hoc으로 나눌 수 있다. priori는 실험 전에 실시하는 것으로 선행연구나 연구가설의 예측이 적중하는지 보고 싶을때 사용한다. 보통 t검정이 priori test로 주로 사용되며 유의미함을 만드는 것으로 추정되는 집단과 아닌 집단으로 수행한다. priori는 post hoc에 비해 1종 오류를 범할 가능성이 높은데, 사실 왜 우리가 t검정을 제쳐두고 분산분석을 하는지 이유를 생각해보면 자연스럽게 그 이유를 알 수 있다. 유일한 이점이라면 그래도 post hoc에 비해 검정력이 높다는게 위안이다.
3.Post Hoc Comparison(Posteriori Comparison)
반면에 Post hoc은 선행연구나 연구가설 없이 실험 후에 실시된다. 물론 분산분석을 떠나서 연구가설 없이 실시한 연구를 찾아볼수 없기 때문에 이는 말이 안되므로, 형식적으로 선행하는 가설이 없어도 가능한 분석이라고 알아듣는 편이 편하다. 정말 수많은 post hoc 검사가 있지만 여기서는 그 중에서도 탑으로 유명한 터키 HSD검사(Tukey Honestly Significant Difference)와 셰페 검사(scheffe test)만 다루겠다.
3.1.튜케이 HSD 검사(tukey HSD test)
튜케이 검사는 각 표본집단의 평균을 서로 짝지어 비교하여 서로가 서로에 대해 유의미한 차이를 보이는지 보여준다. 여기까지만 하면 t검정으로 사후검정하는것과 다를바 없어 보이지만 터키 검사는 Q라는 다른 통계량을 사용하여 t검정과 달리 1종 오류를 최소화한다. 먼저 Q의 공식은 다음과 같다.
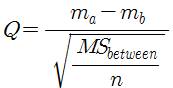
튜케이 검사는 이 Q를 모든 집단을 대상으로 구한다. 즉 2개의 집단이 있으면 튜케이 검사는 1번만 행해지고 4개의 집단이 있으면 터키 검사는 총 6번 행해진다. 토너먼트를 떠올리면 쉽다. Q의 분포는 Studentized range 분포를 따른다. 이 분포는 n과 MSbetween의 자유도에 의해 결정되는데 그래서 유의수준을 결정할때도 n과 MS의 자유도가 필요하다. 그리고 이 Q는 마치 튜케이 검사와 t검정이 비슷하듯 t값과도 비슷해서, 사실 Q=√2t 이다. 암튼 튜케이 검사를 통해 나온 Q는 p를 구하거나, p≤<a일때의 Q와 비교해서 유의한지 구한다. 분산분석의 사후검정에 대해 다루는 책이라면 모두 부록에 Studentized range 분포가 실려있으므로 당신은 그저 n과 MSbetween의 자유도로 부록에서 원하는 값을 찾을수만 있으면 된다.
3.2.셰페 검사
셰페 검사는 가장 전통적인 사후검정 중 하나이다. 이 검사는 Fscheffe값을 요구하는데, 이 값으로 분산분석을 시행하여 비교하는 집단간에 유의미한 차이가 있는지 검증한다. Fscheffe를 구하는 방법은 다음과 같다.

이 값을 분산분석에서 하는 것처럼 검정하면 된다. 검정은 액셀의 FDIST 함수를 사용하면 쉽다.

보는 바와 같이 Fsheffe는 SSbetween을 단지 2개의 집단만 고려한 것만 제외하면 분산분석과 동일하다. 그래서 df(between) 등 분산분석에서 쓰는 다른 변수들을 공유하며 이를 통해 사후검정 중에서 1종 오류를 범할 가능성이 가장 낮다. 그러나 터키 검사는 셰페 검사에 비해 검정력이 높다는 이점이 있어 둘 중 하나를 높이 둘 이유는 없다.
'자료실' 카테고리의 다른 글
| 돈은 어떻게 전능해지는가 (0) | 2022.05.23 |
|---|---|
| 신뢰가능한 국내 언론 리스트 (0) | 2022.05.23 |
| 심리학적 성차에 대한 주관적인 시각 (0) | 2022.05.21 |
| 이기주의의 철학적 문제 (0) | 2022.05.21 |
| 남녀의 성격차이에 대한 대안 가설들 모음 (0) | 2022.05.21 |
